This is a Korean review of "Dataset Condensation with Distribution Matching" presented at WACV 2023.
TL;DR
- DD를 통해 합성된 이미지로 모델을 빠르게 학습할 수 있지만, 이미지 생성 과정은 복잡한 bi-level optimization과 second-order derivatives computation 때문에 계산 비용이 매우 큼.
- 본 논문은 many sampled embedding spaces에서 합성 이미지와 원본 이미지의 feature distribution을 일치시키는 방식으로 이미지를 합성하는, 최초의 distribution matching 기반 dataset distillation 방법을 제안함.
Introduction

- 기존의 다양한 dataset distillation 기법들은 일정 수준의 성능을 보이지만, 대부분 여전히 비용이 큰 bi-level optimization 문제를 내포하고 있음.
- 본 논문에서는 bi-level optimization을 수행하지 않고도, distribution matching을 통해 합성 데이터가 원본 데이터 분포를 다양한 embedding space 상에서 정합되도록 최적화하는 방법을 제안함.
- 이를 위해 분포 간 거리 측정으로 maximum mean discrepancy (MMD)를 사용
- 다양한 embedding space는 무작위로 초기화된 딥러닝 모델들을 샘플링함으로써 효율적으로 구성
- 이 방법은 클래스별로 학습을 독립적으로 수행할 수 있으므로, 병렬 처리 및 계산 부하 분산이 가능하다는 장점이 있음.
Methodology
Dataset Condensation Problem
- Dataset distillation은 large-scale training set $\mathcal{T}$을 small synthetic set $\mathcal{S}$로 압축하는 방법으로, 아래의 식과 같이, $\mathcal{T}$와 $\mathcal{S}$에 학습된 모델이 unseen testing data에서 비슷한 성능을 내는 것을 목표로 함.
$$
\mathbb{E}_{x \sim P_{\mathcal{D}}} \left[ \ell\left( \phi_{\theta^T}(x), y \right) \right]
\simeq
\mathbb{E}_{x \sim P_{\mathcal{D}}} \left[ \ell\left( \phi_{\theta^S}(x), y \right) \right],
$$
Existing Solutions
- Learning-to-learn problem 방식은 network parameters $\theta^\mathcal{S}$을 synthetic data $\mathcal{S}$의 함수로 정의하고, 원본데이터셋 $\mathcal{T}$에 대한 training loss $\mathcal{L}^\mathcal{T}$을 최소화하는 $\mathcal{S}$를 구함.
$$
S^* = \arg\min_\mathcal{S} \mathcal{L}^\mathcal{T}\left(\theta^\mathcal{S}(\mathcal{S})\right)$$ $$
\text{subject to} \quad \theta^\mathcal{S}(\mathcal{S}) = \arg\min_\theta \mathcal{L}^\mathcal{S}(\theta).
$$ - 또 다른 방법으로, 합성 데이터와 실제 데이터에 대해 계산된 gradient를 matching하는 방법이 있음. 이 방법은 파라미터 $\theta$와 합성 데이터 $\mathcal{S}$를 번갈아 최적화하면서 다음의 목표를 최소화함.
$$
\mathcal{S}^* = \arg\min_\mathcal{S} \mathbb{E}_{\theta_0 \sim P_{\theta_0}} \left[ \sum_{t=0}^{T-1} D\left( \nabla_\theta \mathcal{L}^\mathcal{S}(\theta_t), \nabla_\theta \mathcal{L}^\mathcal{T}(\theta_t) \right) \right]
$$ $$
\text{subject to} \quad \theta_{t+1} \leftarrow \text{opt-alg}_\theta\left( \mathcal{L}^\mathcal{S}(\theta_t), \varsigma_\theta, \eta_\theta \right),
$$
Dilemma
- 위의 performance matching과 gradient matching 방법은 고비용의 bi-level optimization 과정을 포함함. 즉, inner loop에서는 모델 $\theta$을 최적화하고, outer loop에서는 *second-order derivative computation을 포함하는 합성 데이터 $\mathcal{S}$를 최적화해야 함.
*모델 파라미터 $\theta$는 합성데이터 $\mathcal{S}$에 의해 영향을 받으므로, $\frac{\partial \mathcal{L}^\mathcal{T}(\theta^*(\mathcal{S}))}{\partial \mathcal{S}} = \frac{\partial \mathcal{L}^\mathcal{T}}{\partial \theta^*} \cdot \frac{\partial \theta^*}{\partial \mathcal{S}}$의 chain rule이 성립함. 여기서 $\theta^*$는 합성데이터 $\mathcal{S}$를 통해 정의된 $\mathcal{L}^\mathcal{S}$에 대해 gradient descent를 수행한 결과로, $\theta^* = \theta - \alpha \nabla_\theta \mathcal{L}^\mathcal{S}(\theta)$로 정의됨. 따라서, $\frac{\partial \theta^*}{\partial \mathcal{S}} = -\alpha \cdot \frac{\partial}{\partial \mathcal{S}} \nabla_\theta \mathcal{L}^\mathcal{S}(\theta) = -\alpha \cdot \nabla^2_{\theta, \mathcal{S}} \mathcal{L}^\mathcal{S}(\theta)$이므로, second-order derivative가 됨.
Dataset Condensation with Distribution Matching
- 훈련 이미지들은 일반적으로 high-dimensional하기 때문에 실제 분포를 추정하고 이를 근사하는 합성 데이터를 생성하는 것은 비용이 많이 들고 부정확함.
- 대신, 본 논문의 방법은 각 학습 이미지 $x\in\mathbb{R}^d$가, parametric function $\psi_\vartheta: \mathbb{R}^d \rightarrow \mathbb{R}^{d'}$를 통해 lower dimensional space로 embedding될 수 있다고 가정함.
- 즉, 각 embedding function $\psi$는 입력 이미지에 대한 부분적인 해석을 제공하며, 이들의 조합은 전체적인 표현을 제공함.
- Maximum mean discrepancy (MMD)를 통해서, 원본데이터와 합성 데이터 간의 분포 차이를 측정할 수 있음.
$$
\sup_{\|\psi_{\vartheta}\|_{\mathcal{H}} \leq 1} \left( \mathbb{E}[\psi_{\vartheta}(\mathcal{T})] - \mathbb{E}[\psi_{\vartheta}(\mathcal{S})] \right)
$$ - Ground-truth data 분포에 접근할 수 없으므로, 아래의 MMD의 empirical estimate를 사용함.
$$
\mathbb{E}_{\vartheta \sim P_{\vartheta}} \left\|
\frac{1}{|\mathcal{T}|} \sum_{i=1}^{|\mathcal{T}|} \psi_{\vartheta}(x_i) -
\frac{1}{|\mathcal{S}|} \sum_{j=1}^{|\mathcal{S}|} \psi_{\vartheta}(s_j)
\right\|^2
$$
- $P_\vartheta$는 네트워크 파라미터의 분포임.
- 이전 연구에서 적용한, 미분가능한 Siamese augmentation $\mathcal{A}(\cdot, \omega)$를 실제 데이터와 합성데이터에 모두 활용하여 최종적인 optimization 문제로 정의하면 다음과 같음.
$$
\min_\mathcal{S} \mathbb{E}_{\vartheta \sim P_{\vartheta}, \omega \sim \Omega}
\left\| \frac{1}{|\mathcal{T}|} \sum_{i=1}^{|\mathcal{T}|} \psi_{\vartheta}(\mathcal{A}(x_i, \omega)) - \frac{1}{|\mathcal{S}|} \sum_{j=1}^{|\mathcal{S}|} \psi_{\vartheta}(\mathcal{A}(s_j, \omega)) \right\|^2
$$ - 이를 통해, 다양한 embedding space (다양한 $\vartheta$)에서 두 분포 차이를 최소화하여 합성 데이터 $\mathcal{S}$를 학습함. 위의 식은, 모델 파라미터를 전혀 학습할 필요 없이 오직 $\mathcal{S}$만을 최적화하므로, bi-level optimization을 피할 수 있음.
- 본 논문은 이미지 분류 문제를 대상으로 하기 때문에, 같은 클래스 내에서 분포 차이를 최소화함. 또한, 모든 실제 학습 샘플은 레이블을 갖고 있으며, 합성 샘플에도 고정된 레이블을 부여함.
Training Algorithm

Discussion
Randomly Initialized Networks
- Embedding 함수 $\psi_\vartheta$의 집합은 다양한 방식으로 설계될 수 있음. 본 논문에서는 사전 학습된 네트워크(많은 계산 비용이 필요)에서 파라미터를 샘플링하는 대신, 무작위로 초기화된 딥러닝 모델을 여러 개 사용하는 방법을 선택함.
- 무작위로 초기화된 네트워크는 강력한 representation을 만들어 내며, 데이터의 *distance-preserving embedding을 수행함.
*같은 클래스의 샘플들은 가까이, 다른 클래스의 샘플들은 멀리 위치하도록 embedding
Connection to Gradient Matching
- Distribution mathcing은 실제 이미지와 합성 이미지 batch의 평균 feature를 일치시키는 반면, gradient matching은 두 batch에서 계산된 평균 gradient를 일치시킴.
- Distribution mathcing은 모든 feature에 균등한 가중치를 주는 반면, gradient matching은 예측이 부정확한 샘플에 더 큰 가중치를 부여함.
Generative Models
- 이미지 생성 기법은 실제처럼 보이는 이미지 생성을 목표로 하지만, dataset distillation은 데이터 효율적인 학습 샘플 생성을 목표로 함. 이미지를 현실적으로 보이도록 하는 제약은 데이터 효율성을 제한할 수 있음.
- 기존 연구는 cGAN으로 생성된 이미지들이, 무작위로 선택한 실제 이미지보다 모델 학습에 더 안좋다는 것을 보여줌.
Experiments
Comparison to the SOTA
Competitors
- Coreset selection 중, Herding은 mean vector가 전체 데이터셋의 mean에 가까워지도록 샘플을 greedily 추가하는 방식
- Forgetting은 네트워크 학습 중 얼마나 자주 샘플이 학습되고 잊혀지는 지 계산하여 less forgetful 샘플은 제외하는 방식
Peformance Comparision

Visualization


- 각 방법들 (DC, DSA, DM)에 의해 학습된 이미지의 feature distribution을 추출하기 위해, 원본 학습데이터에 학습된 네트워크를 활용했음.
- DC와 DSA에 의한 합성 이미지는 실제 이미지 분포를 커버하지 못하지만, DM에 의한 합성 이미지는 실제 이미지 분포를 잘 커버하고 있으며, outlier도 더 적음.
Learning with Batch Normalization

- DSA에서는 작은 합성 데이터 세트의 경우, BN을 사용할 때 정확한 평균과 표준편차 추정이 어렵고, 이를 실제 데이터로 사전 설정하여 고정하면 오히려 최적화가 불안정해지므로, IN이 더 좋은 성능을 보임.
- 반면, DM은 모든 클래스에서 증강된 합성 데이터를 활용하여 합성데이터의 실제 평균과 분산을 직접 추정할 수 있으므로, BN을 안정적으로 사용할 수 있고 성능도 향상됨.
Training Cost Comparison
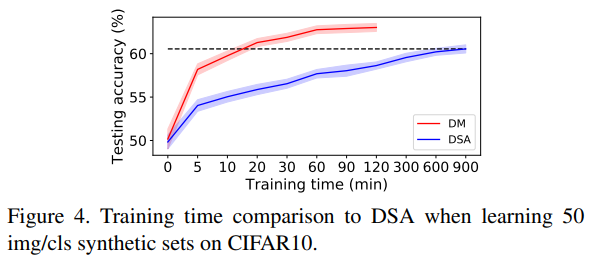
- DM은 bi-level optimization 방법인 DSA보다 훨씬 효율적임.
Learning Larger Synthetic Sets
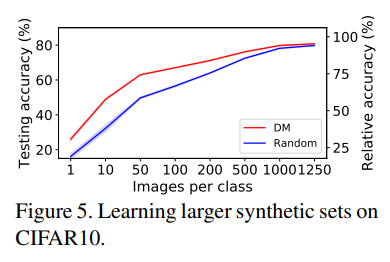
- DSA 같은 bi-level optimization 기반의 방법은 데이터셋이 커질수록 학습시간과 튜닝 비용이 매우 커지지만, DM은 더 큰 합성 데이터셋에서도 효과적으로 학습할 수 있음.
Cross-architecture Generalization
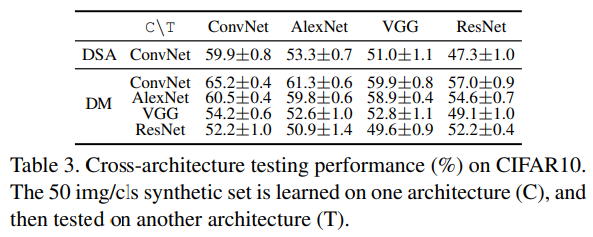
- Distribution matching으로 학습된 합성 이미지는 gradient matching으로 학습된 합성 이미지보다 보지 못한 구조에 대해 더 나은 일반화 성능을 보임.
- ResNet과 같은 복잡한 아키텍처로 합성 데이터를 학습할 경우, 해당 합성 데이터가 그 아키텍처에 과도하게 fitting되어 다른 아키텍처에는 존재하지 않는 bias를 포함하게 되고,이로 인해 타 아키텍처에서 성능이 하락함 (마지막 row).
- 또한, 같은 합성 데이터를 더 복잡한 아키텍처에서 평가할 때도 성능이 더 낮게 나타나는데 (마지막 column), 이는 작은 합성 데이터만으로는 복잡한 모델이 충분히 학습되지 못해 underfitting이 발생하기 때문임.
Conclusion
- 본 논문은 distribution matching에 기반한 최초의 dataset distillation 방법을 제안함. 이 방법은 bi-level optimization이 필요 없어 매우 효율적이며, 대규모 또는 복잡한 데이터셋에도 적용 가능하고, 클래스당 수백~수천 장 규모의 합성 데이터셋도 학습할 수 있음.