This is a Korean review of "Dataset Distillation" presented at arXiv 2018.
TL;DR
- 전체 학습 데이터의 지식을 소수의 합성 데이터로 압축하는 Dataset Distillation 방법을 최초로 제안
Intoduction
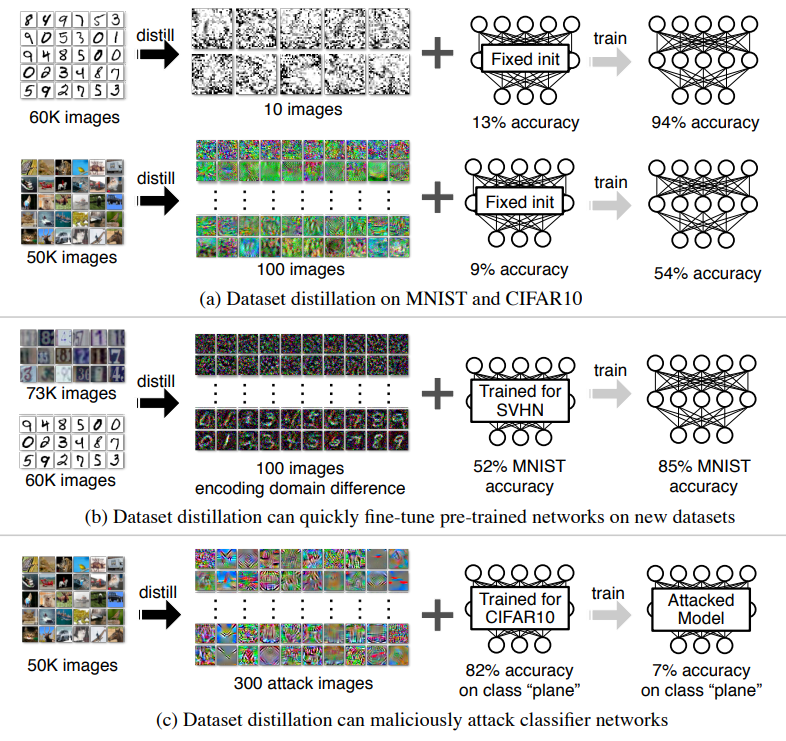
- 본 논문은 고정된 모델에 대해 전체 훈련 데이터셋을 몇 장의 합성 이미지로 압축하는 Dataset Distillation이라는 새로운 과제를 제안함.
- 일반적으로 합성 데이터는 실제 데이터와 분포가 달라 학습에 부적합하다고 여겨지지만, 본 연구는 소수의 synthetic data만으로도 이미지 분류 모델을 효과적으로 학습시킬 수 있음을 보여줌.
- 이를 위해 *모델의 파라미터를 합성 이미지의 미분 가능한 함수로 표현하고, 가중치를 직접 최적화하는 대신 합성 이미지의 픽셀값을 최적화하는 방식을 사용함.
- 다만 이 접근은 초기 파라미터에 대한 접근을 요구하므로, 이를 완화하기 위해 **랜덤 초기화를 고려한 distilled image 생성 방식도 제안함.
- 더 나아가, 여러 에폭에 걸쳐 학습할 수 있는 distilled image 시퀀스를 생성하는 iterative 버전도 함께 제안되어 성능을 추가적으로 향상시킴.
*모델의 업데이트가 합성 이미지에 의해 결정되므로, 이 합성 이미지도 마치 파라미터처럼 최적화하여 real data에서 좋은 성능을 내도록 학습할 수 있음.
**특정 단일 초기 파라미터에서 학습된 합성데이터는 다른 초기 파라미터를 가진 모델에서 성능이 떨어질 수 있으므로, 초기 파라미터를 확률 분포에서 샘플링하여 다양한 초기화에 대응할 수 있음.
Related Works
Dataset pruning, core-set construction, and instance selection
- Dataset pruning, core-set construction, and instance selection 계열의 방법들은 전체 데이터셋 중 모델 학습에 중요한 일부 샘플만 사용하거나, active learning을 통해 의미 있는 샘플만 라벨링하는 방식으로 데이터셋을 압축함.
- 하지만 이러한 방법들은 실제 이미지만을 사용해야 하므로, 클래스당 많은 수의 샘플이 필요함.
Approach
- Sec. 3.1: 고정된 초기값에서 한번의 gradient descent만으로 네트워크를 학습시키시는 optimization 알고리즘
- Sec. 3.2: 랜덤 초기화에서의 optimization
- Sec. 3.4: 여러 번의 gradient descent step과 여러 epoch 학습으로 확장
Optimizing Distilled Data
- sinlge step으로 만든 합성데이터 $( \tilde{\mathbf{x}} )$ 가 실제 데이터 $ (\mathbf{x}) $ 에서도 높은 성능을 달성하기 위해 다음의 수식을 적용함.
$$
\theta_1 = \theta_0 - \tilde{\eta} \nabla_{\theta_0} \ell( \tilde{\mathbf{x}} , \theta_0)
$$ $$
\tilde{\mathbf{x}}^*, \tilde{\eta}^* = \arg\min_{\tilde{\mathbf{x}}, \tilde{\eta}} \mathcal{L}(\tilde{\mathbf{x}}, \tilde{\eta}; \theta_0)
= \arg\min_{\tilde{\mathbf{x}}, \tilde{\eta}} \ell(\mathbf{x}, \theta_1)
= \arg\min_{\tilde{\mathbf{x}}, \tilde{\eta}} \ell\left(\mathbf{x}, \theta_0 - \tilde{\eta} \nabla_{\theta_0} \ell(\tilde{\mathbf{x}}, \theta_0)\right)
$$
Distilation for Random Initialization

- 3.1절에서 제안된 고정된 초기값에 대한 최적화 방법은, 다른 초기값에 대해서는 일반화 성능이 좋지 않음.
- 이러한 distilled data는 랜덤 노이즈처럼 보이기도 하는데 (Fig. 2), 이는 해당 데이터가 훈련 데이터뿐 아니라 특정 초기 가중치까지 암묵적으로 인코딩하고 있기 때문임.
- 따라서, 특정 분포 $ p(\theta_0) $ 로부터 샘플링된 랜덤 초기화 네트워크에서도 잘 작동하도록, 다음과 같은 기대값 기반 최적화 문제를 정의함.
$$
\tilde{\mathbf{x}}^*, \tilde{\eta}^* = \arg\min_{\tilde{\mathbf{x}}, \tilde{\eta}} \mathbb{E}_{\theta_0 \sim p(\theta_0)} \mathcal{L}(\tilde{\mathbf{x}}, \tilde{\eta}; \theta_0)
$$
- 이렇게 얻어진 합성 데이터는 보지 않은 초기화에 대해서도 잘 일반화되며, 각 클래스의 판별적인 특징을 시각적으로 잘 담고 있는 정보량 높은 이미지들로 나타남 (Fig. 3).

- 다만, 이 방법이 잘 작동하기 위해서는, 초기화 $ \theta_0 \sim p(\theta_0) $에 따라 손실 함수가 가지는 로컬 조건 (예: 손실 함수의 곡률, gradient 크기, 업데이트 방향 등)이 유사해야 해야 함. → 그래야 같은 합성 이미지를 사용해도 모델이 전혀 다른 방향으로 업데이트되는 문제를 피할 수 있음.
¶Analysis of A Simple Linear Case
- 선형 회귀 문제 분석을 통해, 한번의 gradient descent step으로 어떠한 초기화에도 잘 작동하는 합성 데이터를 만들기 위해서는 (i.e., 정확한 global minimum을 달성하기 위해서는), 합성 데이터 수가 feature 차원 수 이상이어야 함. → 실제 이미지 데이터는 수천~수십만 차원이기 때문에 현실적으로는 제한적임.
- 따라서, $ p(\theta_0) $ 분포를 적절하게 제한하여, 유사한 로컬 조건을 가지는 초기화들만 적용해야 실용적인 학습이 가능함. → 여러 번의 gradient descent step과 여러 epoch 학습으로 확장 필요
¶원문 참고
Multiple Gradient Descent Steps and Multiple Epochs
- 단일 gradient descent step만으로는 학습이 부족하므로, 이를 여러 단계로 확장하여 다음과 같이 학습을 수행함.
$$
\theta_{i+1} = \theta_i - \tilde{\eta}_i \nabla_{\theta_i} \ell(\tilde{\mathbf{x}}_i, \theta_i)
$$ - Multiple epoch은 위의 gradient descent step 시퀀스 전체를 여러 번 반복하는 것으로 구현됨.
Experiments
Dataset Distillation
Fixed initialization and Random initialization

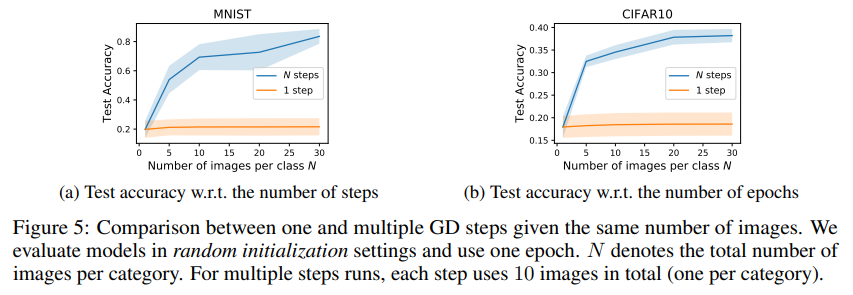
Multiple gradient descent steps and multiple epochs
- 초기 step에서는 이미지가 noise가 가까워 보이지만, 이후에는 real data처럼 보이고, 각 클래스에 대한 discriminative feature를 공유함 (Fig. 3).
- 더 오래 (more steps), 더 반복 (more epoch) 해서 학습할수록 모델은 distilled image로부터 더 많은 지식을 흡수할 수 있음.

- 동일한 distilled image에서, multiple steps을 사용하는 것이 sinlge step을 사용하는 것보다 더욱 뛰어난 성능을 보여줌.
Discussion
- 본 논문은 전체 학습 데이터의 지식을 소수의 합성 데이터로 압축하는 Dataset Distillation 방법을 최초로 제안함.
- 제안된 방법은 small distillaed image와 several gradient descent step만으로 높은 분류 성능을 달성할 수 있음.
- 향후에는 ImageNet과 같은 대규모 시각 데이터뿐만 아니라, 오디오·텍스트 등 다양한 데이터 형태로의 확장이 필요함.
- 현재 방법은 모델 초기화 분포에 민감하다는 한계가 있음. → 보다 강건한 초기화 전략에 대한 추가 연구가 필요함.