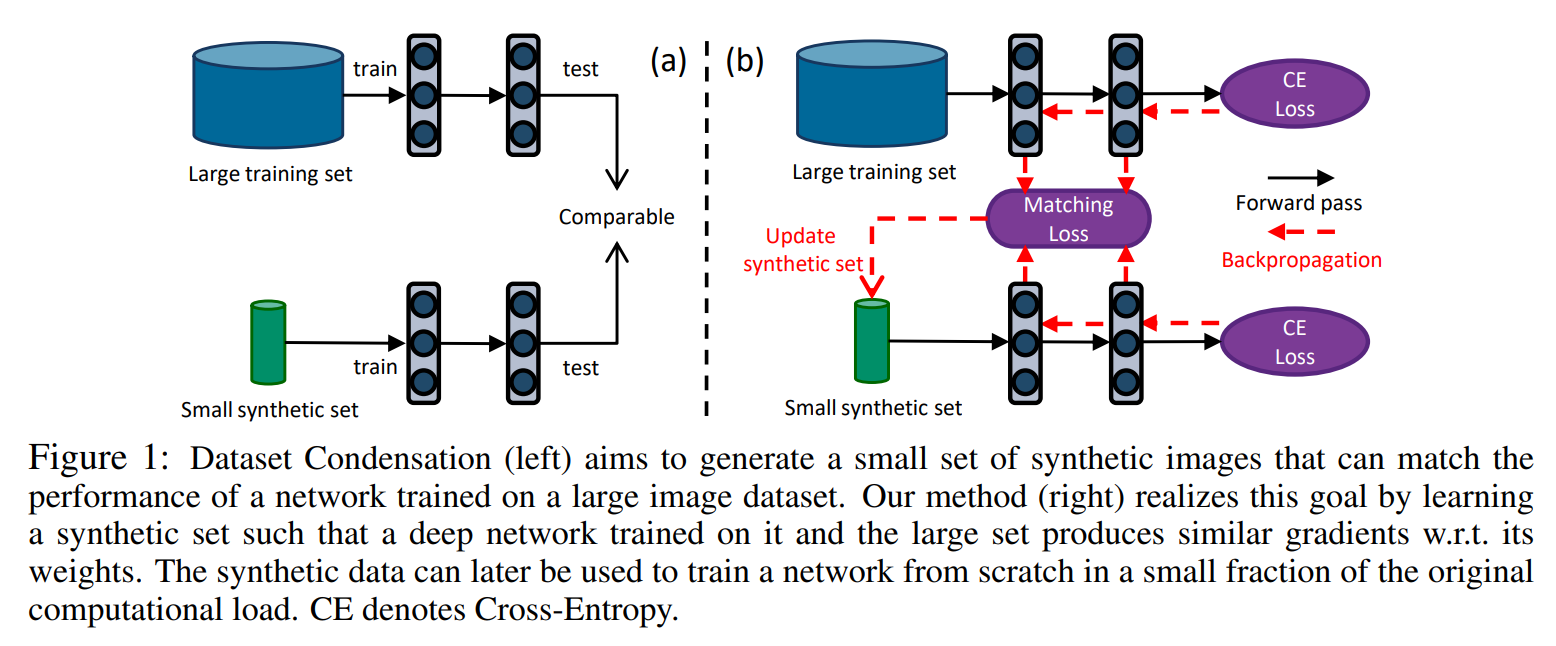
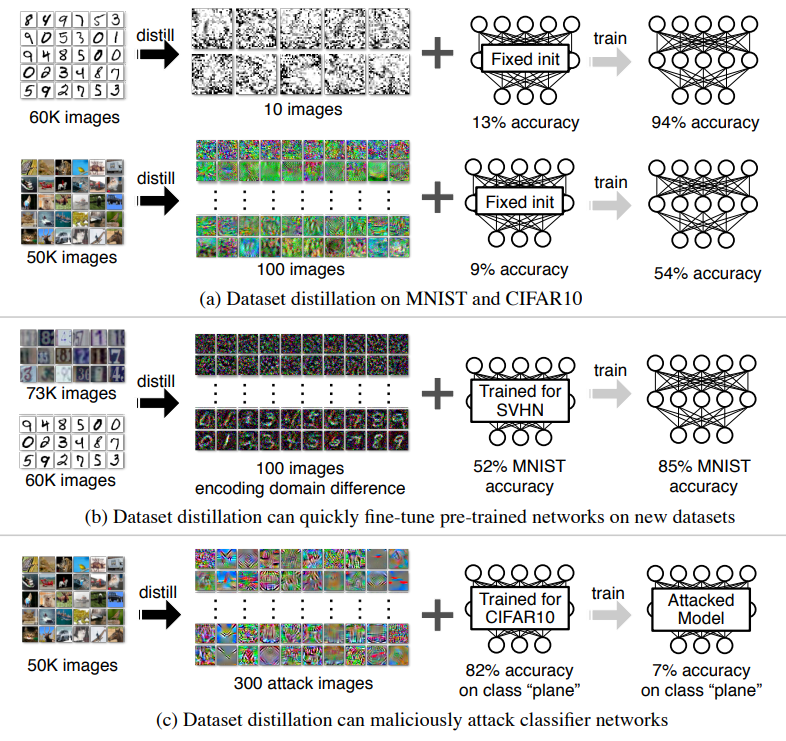
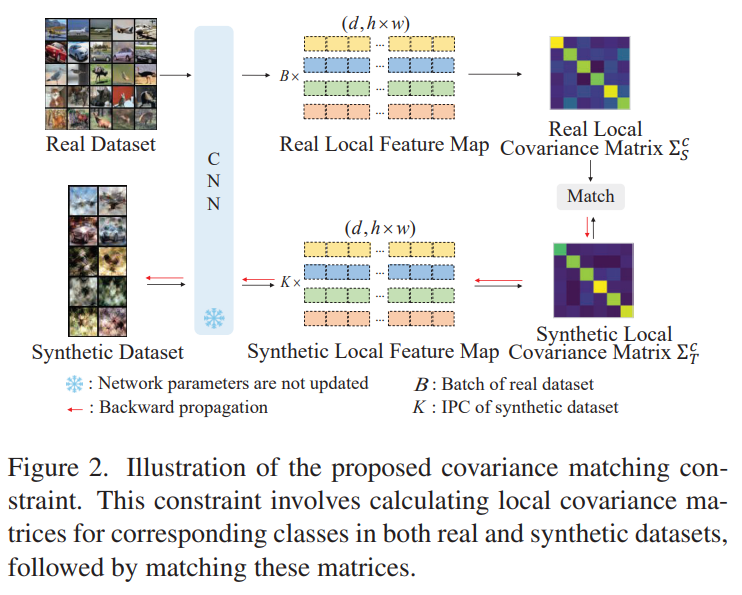
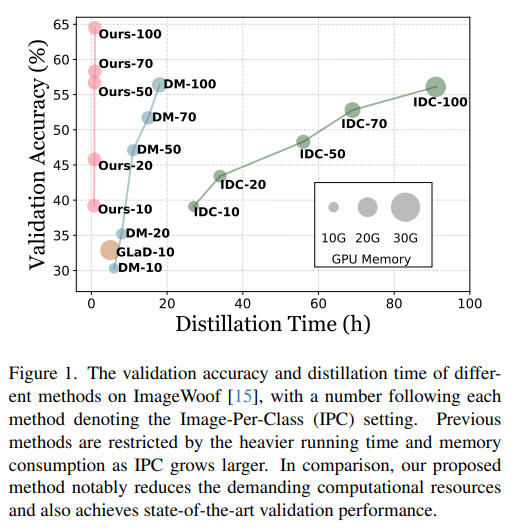
This is a Korean review of "What Makes a Good Dataset for Knowledge Distillation?" presented at CVPR 2025. TL;DR일반적인 KD는 학생 모델을 학습할 때, 선생 모델이 학습한 원본 데이터셋을 사용할 수 있다는 가정이 있지만, 실제 application에서는 항상 가능한 것이 아님.이를 극복하기 위해, 'supplemental data'를 사용하는 것을 고려할 수 있음. 그렇다면, 어떤 데이터셋이 지식을 전달할 때에 좋은 데이터셋일까?Real하고, In-domain dataset 만이 유일한 방법이라고 생각할 수 있지만, 본 연구를 통해, unnatural synthetic dataset도 대안이 될 수 있음을 보임. ..