This is a Korean review of
"Efficient Dataset Distillation via Minimax Diffusion"
presented at CVPR 2024.
TL;DR
- Original large-scale dataset을 대체할 수 있는 small dataset을 만드는 기법인 dataset distillation의 기존 방법들은 sample-wise iterative optimization 기법에 크게 의존함.
- 따라서, images-per-class $($IPC$)$ setting 또는 image resolution이 커지게 되면, 과도한 시간과 자원이 요구됨.
- Generatvie diffusion 기법을 활용하며, 효과적인 small dataset의 핵심요소가 대표성$($representativeness$)$와 다양성$($diversity$)$임을 관찰함으로써, minimax criteria를 설계함.
IPC: 각 class당 포함된 요약 이미지의 개수를 의미, dataset distillation의 중요 paramter
e.g., IPC=1이라면, 각 class당 하나의 이미지를 생성
Introduction
- Dataset distillation은 large-scale dataset의 풍부한 정보를 small dataset에 압축하는 기법으로, 기존 dataset에 의해 학습된 성능과 유사한 성능을 얻을 수 있음.
- 기존의 dataset distillation 방법들은 fixed-number sample에 대한 iterative optimization을 수행하는데, 이는 아래의 두 가지 문제가 존재함.
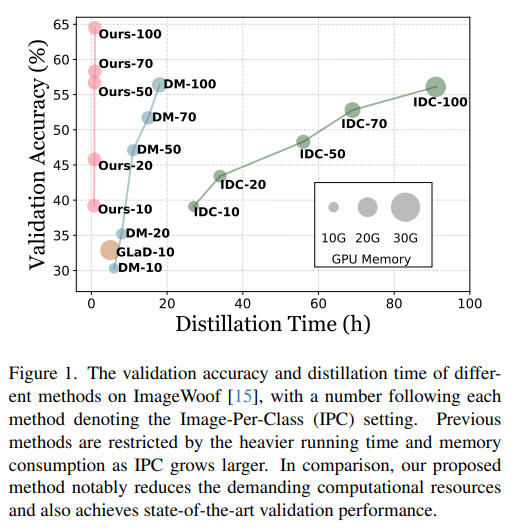
- Optimization의 parameter space가 small dataset 및 image resolution과 positively corrleation 되어 있어, 상당한 시간과 computational 자원이 요구됨.
- 확장된 parameter space는 optimization 복잡성도 증가시킴. 그림 2를 통해, larger-IPC dataset를 distillation 할 때 pixel modification이 줄어드는 것을 확인할 수 있음. Reduced disparity로 인해 아주 작은 성능 향상 또는 성능이 오히려 떨어지는 경우를 초래함.

- 따라서, 이전의 기법으로 Fine-grained class를 포함하는 dataset를 distillation 하면, 적절한 discriminative information를 제공하지 못함. 이는 personalized dataset을 활용하는 실제 application에서 distillation 하는 것을 어렵게 함.
- 본 논문은 효율적인 surrogate dataset을 만들기 위해 generative difuusion 기법을 적용하며, raw diffusion model을 통해 만들어진 sample에 대한 empirical 분석을 통해, representativeness와 diversity의 중요성을 확인함.
- 이에 따라, 추가적인 minimax criteria를 제안함. 이는 generated sample이 real sample에 가깝도록 강제하는 동시에, generative sample과는 멀리 떨어지도록 함. 이를 support하기 위해 theoretical analysis를 제시함.
- 이전 방법들과 비교할 때, 제안 방법은 10-class ImageNet subset에 대한 100-IPC small dataset을 만드는 데에 1시간 소요되며, GPU 소비량은 모든 IPC setting에 대해 일관되게 유지함. 동시에, distilled small dataset은 가장 뛰어난 성능을 기록함.
Method
Problem Definition
- Dataset distillation의 목적은 large-scale datset $\mathcal{T}=(\mathbf{x}_i, y_i)^{N_T}_{i=1}$으로부터 small surrogate dataset $\mathcal{S}=(\mathbf{x}_i, y_i)^{N_S\ll N_T}_{i=1}$를 만드는 것임.
- Surrogate dataset $\mathcal{S}$은 original dataset $\mathcal{T}$의 많은 정보를 요약하며, $\mathcal{T}$로 학습된 성능과 유사한 성능을 얻도록 함.
- Distillation 후, $\mathcal{S}$에 대해서 network를 training 하고, original testset에 대해서 성능을 validation 함.
Diffusion for Distillation
- Diffusion model은 image에 Gaussin noise를 점차적으로 포함시키며 datset distribution을 학습하고, 이를 역변환하는 과정임.
- Latent diffusion model $($LDM$)$을 예시로, training 과정은 두 부분으로 분리됨. Encoder $E$는 image를 latent space $\mathbf{z}$로 변환하는 부분, $\mathbf{z}=E(\mathbf{x})$, 이고, decoder $D$는 latent code로부터 image space를 재구성, $\mathbf{\hat{x}}=D(\mathbf{z})$, 하는 부분임.
- Forward noising 과정은 점차적으로 noise $\epsilon \sim \mathcal{N}(0,\mathbf{I})$를 original latent code $\mathbf{z_0}$에 포함시키며, 이는 $\mathbf{z}_t = \sqrt{\bar{\alpha}_t}\mathbf{z}_0 + \sqrt{1-\bar{\alpha}_t}\epsilon$으로 표현할 수 있음.
- 특정 class에 속하도록 조절하는 conditioning vector $\mathbf{c}$를 포함하여, diffusion model은 training 하기 위해 predicted noise $\epsilon_\theta (\mathbf{z}_t, \mathbf{c})$와 ground truth $\epsilon$간의 squared error를 활용함.
$$ \mathcal{L}_\text{LDM}= || \epsilon_\theta (\mathbf{z}_t, \mathbf{c}) - \epsilon ||^2_2$$
- 추가적으로, model이 특정 data domain에 잘 적응하도록, 소수의 model parameter만을 update 하는 Parameter Efficient Fine-Tuning $($PEFT$)$ 기법이 존재함.
- 본 논문에서는 baseline으로 DiT를, naive fine-tuning 방법으로 DiffFit를 적용함.
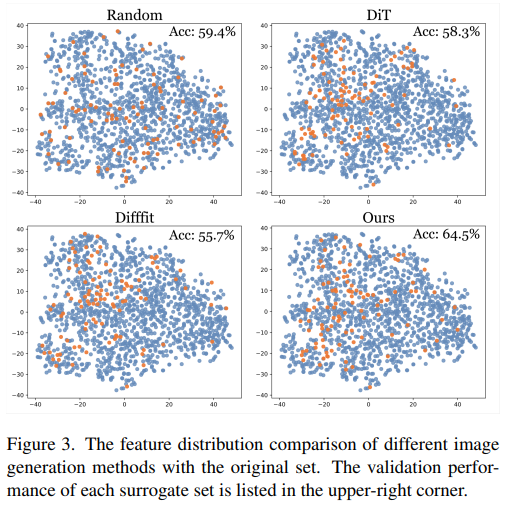
- Randomly selected sample과 diffusion-generated sample은 distribution의 양극단을 나타냄. Random selection은 original distribution을 반영하지만 $(\text{diversity} \uparrow)$, high-density region을 포착하지 못하는 $(\text{representiativeness}\downarrow)$ 반면, diffusion model은 dense area에 over-fit $(\text{representiativeness}\uparrow)$ 하지만, original distribution의 넓은 부분을 cover하지 못함 $(\text{diversity} \downarrow)$ .
- 즉, randomly selected data는 뛰어난 diversity를 가지는 반면, diffusion-generated sample은 뛰어난 representativeness를 보여줌.
- 효과적인 surrogate dataset을 얻기 위해 diversity와 representativeness가 모두 중요하기 때문에, 이러한 특성들을 향상하기 위해 extra minimax criteria를 제안함.
Minimax Diffusion Criteria

Representativeness
- Small surrogate dataset이 original data를 충분히 표현하는 것은 중요한 요소임. representativeness를 향상하는 가장 naive 한 방법은 syntetic sample과 real sample 간의 embedding distribution을 일치시키는 것임.
- Cosine similarity $\sigma(\cdot, \cdot)$, predicted original embedding $ \mathbf{\hat{z}}_\theta (\mathbf{z}_t, \mathbf{c}) = \mathbf{z}_t - \epsilon_\theta (\mathbf{z}_t, \mathbf{c}) $를 활용하여, 아래의 식으로 표현할 수 있음.
\[ \mathcal{L}_r = \arg\max_{\theta} \sigma \left( \mathbf{ \hat{z} }_\theta(\mathbf{z}_t, \mathbf{c}), \frac{1}{N_B} \sum_{i=0}^{N_B} \mathbf{z}_i \right) \]
- 하지만, 이 방법은 predicted embedding을 real distribution의 중심에 모이게 만들어 diversity를 심각하게 제한함.
- 따라서, 이전 iterations에서 활용한 real sample embedding을 저장하는 auxiliary real embedding memory $ \mathcal{M} = \left\{ \mathbf{z}_m \right\}_{m=1}^{N_M} $를 만들어 아래의 minimax optimization objective를 설계함.
$$ \mathcal{L}_r = \arg\max_{\theta} \min_{m\in [N_M]} \sigma (\mathbf{\hat{z}}_\theta (\mathbf{z}_t, \mathbf{c}), \mathbf{z}_m)$$
- Predicted embedding이 가장 유사하지 않은 sample$($real sample embedding$)$과 가깝게 함으로써$(\because \min_{m\in [N_M]} \sigma(\cdot, \cdot))$, original distribution을 잘 cover 하는 image를 생성할 수 있으며, diffusion training objective $\mathcal{L}_\text{LDM}$ 자체가 original image와 유사하도록 만들기 때문에 minimax criterion는 최대한으로 diversity를 보장함.
Diversity
- Diffusion model에 의해 만들어진 data는 original distribution을 정확하게 반영하는 동시에, 서로 달라야 함. 따라서 이전 iterations에서의 predicted embeddings를 포함하는 auxiliary memory $ \mathcal{D} = \left\{ \mathbf{z}_d \right\}_{d=1}^{N_D} $ 를 만들어 sample diversity를 향상하는 또 다른 minimax objective를 설계함.
$$ \mathcal{L}_d = \arg\max_{\theta} \max_{d\in [N_D]} \sigma (\mathbf{\hat{z}}_\theta (\mathbf{z}_t, \mathbf{c}), \mathbf{z}_d)$$
- Predicted embedding이 가장 유사한 sample $($predicted embedding$)$으로부터 멀어지도록 함 $(\because \max_{d\in [N_D]} \sigma (\cdot, \cdot))$ . 비록 diversity가 효과적인 surrogate set에 필수적이지만, 과도하면 representativeness를 잃을 수 있음. 따라서, 제안한 minimax optimization은 class-realted feature에 미치는 영향을 최소화하며, diversity를 적당하게 향상함.
$$ \mathcal{L} = \mathcal{L}_{\text{LDM}} + \lambda_r \mathcal{L}_r + \lambda_d \mathcal{L}_d $$
Theoretical Analysis
Experiments
Comparison with SOTA Methods
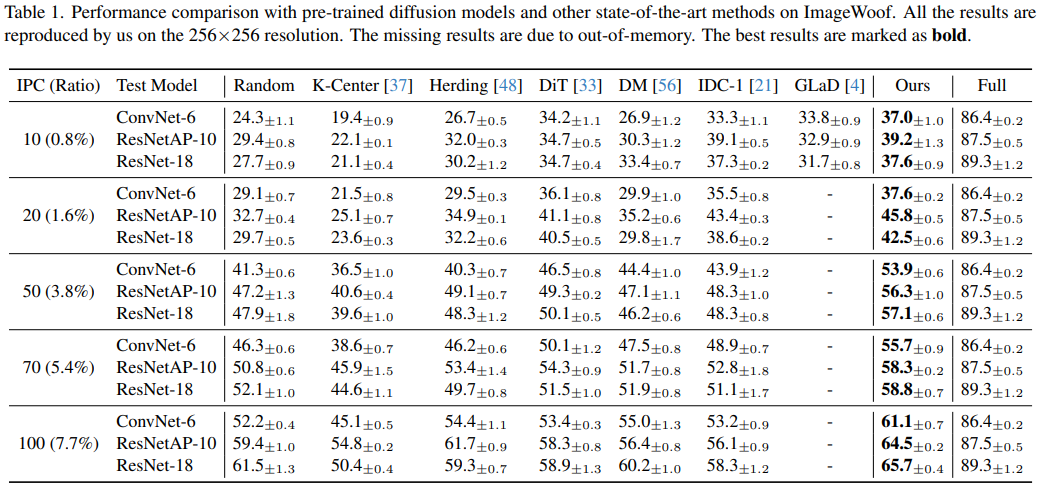
- IPC가 10과 20일 때처럼, 작은 IPC일 때는 pixel-level optimization method인 IDC-1이 random original image보다 뛰어난 성능을 기록하지만, IPC가 커질수록, 성능이 급격히 감소하고, IPC=100일 때는 random original image보다 낮은 성능을 기록함. 이는 pixel-level optimization method가 큰 IPC에서의 확장된 parameter space를 최적화하기 어렵기 때문임.
- 또한, embedding-level optimization method인 GLaD도 IPC=10일 때는 뛰어난 성능을 제공하지만, 높은 IPC에서는 과도한 GPU 자원이 필요하므로, 자원이 제한된 상황에서는 적용하기 어려움.
- Baseline으로 활용한 DiT 또한 IPC=50에서는 random original image과 IDC-1 보다 높은 성능을 제공하지만, 부족한 representativeness와 diversity로 인해 더 낮거나 높은 IPC에서 성능 개선이 제한됨.
- 반대로, minimax diffusion은 모든 IPC에서 original image와 Herding 보다 뛰어난 성능을 기록하며, *matching training metric을 위한 특정 network가 필요하지 않기 때문에, cross-architecture generalization이 상당히 향상됨. 따라서, 대부분의 IPC에서 ConvNet-6과 ResNetAP-10간의 성능 차이가 original image의 성능차이보다 훨씬 작음.
*ResNet-10이 matching feature distribution $($DM, GLaD$)$와
training gradient $($IDC-1$)$를 위해 사용됨.
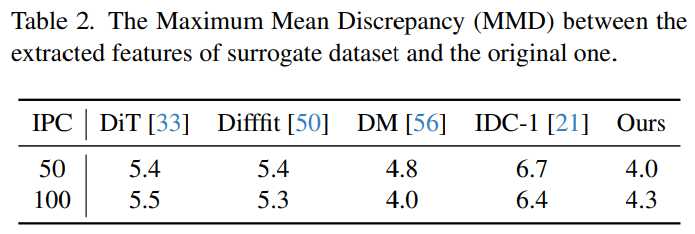
- Table 2는 original dataset과 surrogate dataset의 embedded feature 간의 Maximum Mean Discrepancy$($MMD$)$를 측정함. 비록 DM이 MMD를 optimization target으로 직접 사용하지만, 제안한 방법이 평균적으로 가장 작은 discrepancy를 얻음.
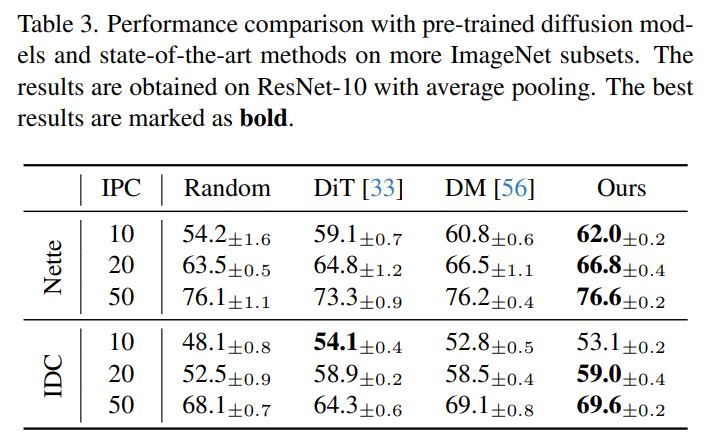
- 유사성이 낮은 class를 포함하여 분류하기 쉬운 dataset인 ImageNette과 ImageIDC에 대해서, DiT는 IPC가 커질수록 original image보다 성능이 급격히 낮아짐.

Ablation Study

Component Analysis
- 어려운 task인 ImageWoof에 대해서, IPC가 10 또는 20일 때, DiT의 성능이 randomly selected original sample보다 높지만, IPC가 증가할수록 성능 격차가 줄어들며, IPC=100에서는 random original image가 성능 역전함.
- 쉬운 task인 ImageIDC에 대해서는, IPC=50일 때부터 random original image가 성능을 역전함.
- DiffFit 방법 역시, large IPC에서 original image보다 성능이 떨어짐.
- Representativeness 제한조건을 추가하면, distribution fitting 효과가 향상되어 낮은 IPC에서 풍부한 정보를 가지게 하지만, 높은 IPC에서는 다양성이 떨어져 성능이 낮음. 여기에 diversity 제한조건을 포함시키면 이를 개선함. 따라서, representativenss와 diversity 모두 효과적인 surrogate dataset을 만드는 데 중요한 부분임.
Minimax Scheme

- 첫 번째 줄은 navie DiffFit fine-tuning의 성능이고, 두 번째 줄은 distribution center에 embedding을 matching 시키는 representativeness loss를 사용한 성능임. 모든 IPC에서 낮은 성능을 기록함.
- 세 번째 줄의 minimax가 포함된 representativeness loss를 사용하면, 낮은 IPC에서 성능이 개선되고, diversity loss w/ minimax를 적용하면 모든 IPC에 걸쳐 뛰어난 성능을 보여줌.
Visualization
Sample Distribution Visualization
- 그림 3에서, 제안한 minimax 방법은 전체 데이터 분포를 더 잘 아우르면서도, sample density를 일관되게 유지함. Original high-density region에서는, random sampling은 하지 못했던, dense sub-cluster를 형성함. 반면, original sparse region에서는 baseline diffusion model보다 더 나은 coverage를 보여줌.
Generated Sample Comparison

- Baseline DiT는 사실적인 high-quality appearance를 표현하지만, 비슷한 pose를 가지고, object의 most prominent features를 제시함. 예를 들어, 골든 리트리버의 경우 머리 부분이 생성되고, 교회는 외관 위주로 생성됨.
- DiffFit fine-tuning을 통해 분포에 더 잘 맞추지만, 차이는 거의 없음.
- 반면, minimax 방법은 entire original distribution을 잘 coverage 하기 때문에 더 class-related content가 포함됨. 골든 리트리버의 경우 몸 부분이, 교회는 내부도 포함됨을 확인할 수 있음.
- 또한, diversity가 향상되어 pose, background, appearance style이 다양해짐.
Training Curve Visualization

- 오랜 training은 $($too much training epoch$)$은 과도한 diversity를 model에 주입시켜 성능 하락을 야기시킴.
Parameter Analysis
Objective Weight
- Representativeness weight $(\lambda_r)$ 변화는 작은 IPC에서 무시할만한 작은 성능 폭을 보여주며, 큰 IPC에서도 상대적으로 안정적인 성능을 보여줌.
- 적절한 범위의 diversity weight $(\lambda_d)$에서 성능이 안정적이지만, diversity를 계속 증가시키면 representativeness의 부족을 초래함.
Memory Size
- Memory size $(N_M)$는 objective 계산에 포함되는 sample 수에 영향을 미치며, 많은 sample이 있을수록 많은 representative information을 포함시킴. 적절한 범위의 memory size를 사용함으로써 낮은 storage burden으로, 안정적인 성능 향상을 얻을 수 있음.
Conclusion
- Generative diffusion 기술에 기반한 dataaset distillation 방법을 제안하며, extra minimax criteria를 통해 surrogate dataset의 representativeness와 diversity를 향상함.