This is a Korean review of
"Instance-conditional knowledge distillation for object detection"
presented at NeurIPS 2021.
Introduction
- High performance의 Deep Learning Networks의 성능을 얻기 위해서는, 불가피하게 많은 양의 parameters를 수반하게 되며, 이는 high computational cost와 memory를 요구함.
- 따라서, Resource-limited devices에서 object detection과 같은 실용적인 application을 사용하기 위해, network pruning, quantization, mobile architecture design, 그리고 knowledge distillation $(\text{KD})$의 방법들이 등장함.
- 그 중에서 KD는 추가적인 inference time 부담과 수정없이 network의 효율성과 성능을 개선시킬 수 있기 때문에 많이 적용됨.
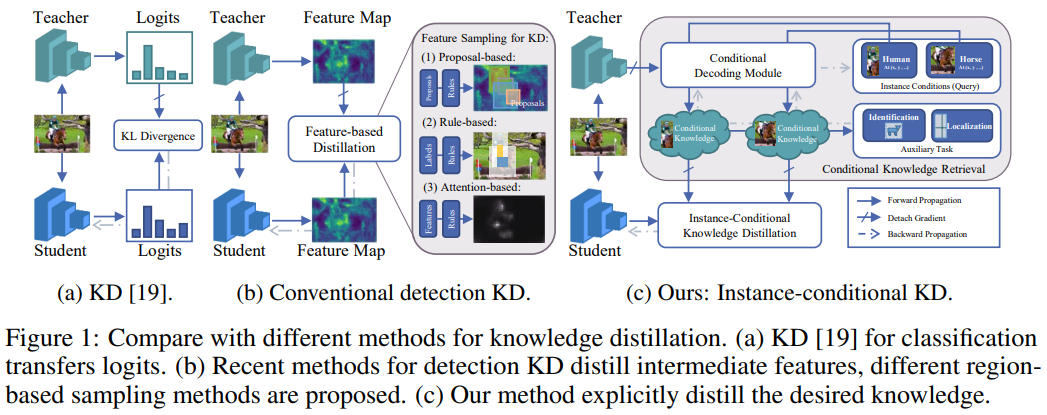
- 지금까지의 많은 KD들은 image classification에 집중되어 연구가 진행되었고, 다음의 이유로 인해 이를 object detection에 그대로 적용하기는 힘들다고 알려져 있음.
- 물체의 localization이 고려되지 않음.
- 서로 다른 위치에 분포되어 있는 여러개의 물체들이 하나의 이미지에 나타나 있음. $($서로 다른 위치로부터의 representation은 서로 다른 contribution를 가지므로 distillation를 어렵게함, i.e., imbalance issue$)$.
- 이를 해결하기 위해 기존의 논문들은 다음과 같은 방법을 적용함.
- classification과 localization에 대한 정보를 함께 가진 intermediate representations를 distillation.
- imbalance 문제를 해결하기 위해 different feature selection 방법을 사용함.
- Proposal-based: RPN에 의해 예측된 proposal regions이나 detector를 활용
- Rule-based: pre-design된 rule로 선별된 regions을 활용; 하지만, 이러한 방법들은 유익한 informative regions를 무시함.
- Attention-based: discriminative area에 대한 hints를 제공하지만, detection을 위한 activation과 knowledge사이의 관계가 clear하지 않음.
- 이에 따라, 본 논문에서는 Instance-Conditional knowledge Distillation $(\text{ICD})$를 제안함으로써, knowledge를 feature selection과 연결하는 explicit solution을 제공함.
- 이를 위해, transformer decoder를 통해 instance-aware attention으로 지식과 각 instance 사이의 correlation을 측정함으로써, 서로 다른 instance와 관련된 지식을 찾도록 하는 conditional decoding module를 설계함.
- 여기서, 사람이 관찰한 instance를 query로 사용하고, teacher's representation $($decomposed into key and value$)$과의 사이를 scaled-product attention을 통해 correlation을 계산함.
- 결과적으로, decoder를 통해 구분된 features들을 distillation하고, instance-aware attention을 통해 weighted됨.
Related Works
Object Detection
- Object detection에서의 detector은 크게 two-stage 또는 one-stage detectors로 구분할 수 있음. Two-stage는 일반적으로 Region Proposal Network $(\text{RPN})$ 을 사용하여, 초기의 대략적인 prediction을 얻고, detection heads를 통해 이를 refine하는 과정을 거침. 대표적으로 Faster F-CNN이 있음. 반면, one-stage detectors의 경우, feature map에 대해 바로 예측을 하기 때문에 더 빠르다고 알려져 있음. 대표적으로 RetinaNet이 있음.
Method
Overview
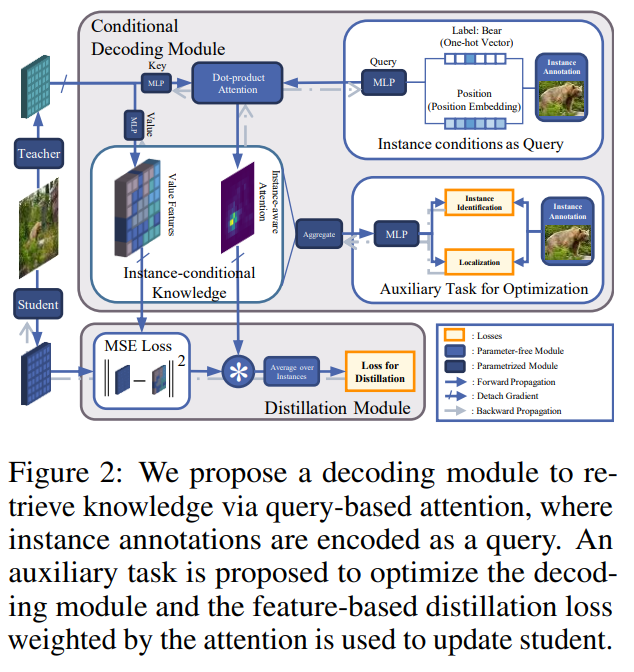
- 일반적으로, detection의 유용한 지식들은 intermediate features에 불균등하게 분포되어 있음. 이를 개선하기, 다음과 같은 식을 통해, instance-conditional knowledge를 전달함.
$$
\mathcal{L}_\text{distill}=\sum_{i=1}^N \mathcal{L}_d\left(\kappa_i^{\mathcal{S}}, \kappa_i^{\mathcal{T}}\right)
$$
- 여기서, $\kappa_i^\mathcal{T}=\mathcal{G}(\mathcal{T},\mathrm{y}_i)$는 condition $(\mathrm{y}_i)$과 teacher representations $(\mathcal{T})$에 대한 knowledge를 의미하고, $\mathcal{G}$는 instance-conditional decoding module를 나타내며, 이는 auxiliary loss를 통해 최적화됨.
Instance-Conditional Knowledge $(\kappa_i)$

- Instance-conditional decoding module $(\mathcal{G})$을 통해 instance condition이 주어졌을 때, unconditional knowledge $(\mathcal{T})$로부터 instance-conditional knowledge $(\kappa^\mathcal{T}_i)$를 구할 수 있음.
- Unconditional knowledge $(\mathcal{T})$는 teacher detector로부터 사용가능한 모든 정보를 의미함. Multi-scale representations로 나타내면 $\mathcal{T}=\left[X_p\in\mathbb{R}^{D \times H_p \times W_p}\right]_{p\in\mathcal{P}}$가 되며, 여기서 $\mathcal{P}$는 spatial resolutions, $D$는 channel dimension을 의미함. Spatial dimension를 따라 서로 다른 scales의 representations을 concatenation하게 되면 $A^\mathcal{T}\in\mathbb{R}^{L\times D}$가 되며, 여기서 $L=\sum_{p\in\mathcal{P}}H_p\times W_p$는 scale를 걸쳐서 모든 pixels의 수를 합한 것임.
- Instance condition은 $\mathcal{Y}=(\mathrm{y}_i)^N_{i=1}$로 나타내며, 여기서 $N$는 object의 수를, $\mathrm{y}_i=(c_i,\mathbf{b}_i)$는 $i$-th instance에 대한 annotation를 의미함. 즉, category $c_i$와 box location $\mathbf{b}_i=(x_i,y_i,w_i,h_i)$임.
- 각 instance에 대해 학습가능한 embedding를 만들기 위해, annotation을 hidden space상에서의 query feature vector $(\mathbf{q}_i)$로 mapping하게 되며, 이때 아래의 식처럼, 원하는 knowledge를 얻기위해 condition을 지정하게 됨.
$$
\mathbf{q}_i=\mathcal{F}_q(\mathcal{E}(\mathrm{y}_i)),\quad\mathbf{q}_i\in\mathbb{R}^D
$$
- 여기서 $\mathcal{E}(\cdot)$는 instance encoding function을, $\mathcal{F}_q$는 MLP를 나타냄.
- $\mathbf{q}_i$가 주어졌을 때, $\mathcal{T}$로부터의 knowledge를 찾기 위해서 correlation을 측정하는데, 이는 dot-product attention을 사용하여 얻을 수 있으며, 각 head $j$는 3개의 선형 layers $(\mathcal{F}^k_j,\mathcal{F}^k_q,\mathcal{F}^k_v)$에 상응함.
- 아래의 식과 같이, key feature $(\mathrm{K}^\mathcal{T}_j)$는 teacher의 representation $(\mathrm{A}^\mathcal{T})$를 positional embeddings $(\mathrm{P}\in\mathbb{R}^{L\times d})$과 projection하여 계산할 수 있음.
$$
\mathrm{K}_j^{\mathcal{T}}=\mathcal{F}_j^k\left(\mathrm{A}^{\mathcal{T}}+\mathcal{F}_{p e}(\mathrm{P})\right), \mathrm{K}_j^{\mathcal{T}} \in \mathbb{R}^{L \times d}
$$
- 여기서, $F_{pe}$는 position embeddings를 통한 선형 projection을 의미하며, value feature와 query는 아래와 같음.
$$
\mathrm{V}_j^{\mathcal{T}}=\mathcal{F}_j^v\left(\mathrm{A}^{\mathcal{T}}\right), \quad \mathrm{V}_j^{\mathcal{T}} \in \mathbb{R}^{L \times d}
$$
$$
\mathbf{q}_{i j}=\mathcal{F}_j^q\left(\mathbf{q}_i\right), \quad \mathbf{q}_{i j} \in \mathbb{R}^d
$$
- 마지막으로, $j$-th head에 의한 $i$-th instance의 instance-aware attention mask $\mathbf{m}_{ij}$는 $\mathrm{K}_j^\mathcal{T}$와 $\mathbf{q}_{ij}$사이의 normalized dot-product를 통해 구할 수 있음.
$$
\mathbf{m}_{i j}=\operatorname{softmax}\left(\frac{\mathrm{K}_j^{\mathcal{T}} \mathbf{q}_{i j}}{\sqrt{d}}\right), \mathbf{m}_{i j} \in \mathbb{R}^L
$$
- 최종적으로, querying along the key feature $(\mathbf{m}_{i j})$와 value features $(\mathrm{V}_j^{\mathcal{T}})$는 representations과 instances간의 correlation을 의미하기 때문에 instance-condition knowledge는 $\kappa_i^{\mathcal{T}}=\left\{\left(\mathbf{m}_{i j}, \mathrm{V}_j^{\mathcal{T}}\right)\right\}_{j=1}^M$가 되며, 이는 $i$-th instance에 상응하는 knowledge를 encoding함.
Auxiliary Task
- 앞서 설명한 decoding module $(\mathcal{G})$을 최적화하기 위해 auxiliary tasks를 활용함. 우선, 함수 $\mathcal{F}_\text{agg}$로 instance-conditional knowledge를 통합 $($instance-level aggregated information $\mathbf{g}_i^{\mathcal{T}})$하여 객체를 식별하고 위치를 파악할 수 있음.
- 여기서, 함수 $\mathcal{F}_\text{agg}$는 attention $\mathbf{m}_{ij}$와 $\mathrm{V}^\mathcal{T}_j$에 대한 sum-product aggregation, 각 head로부터의 features concatenation, residual add, feed-forward networks를 통한 project를 포함함.
$$
\mathbf{g}_i^{\mathcal{T}}=\mathcal{F}_\text{agg}\left(\kappa_i^{\mathcal{T}}, \mathbf{q}_i\right), \mathbf{g}_i^{\mathcal{T}} \in \mathbb{R}^D
$$
- Instance-level aggregated information $\mathbf{g}_i^{\mathcal{T}}$이 충분한 instance 단서를 유지하도록 하기위해, 아래와 같이 instance-sensitive tasks를 사용하여 최적화함.
$$
\mathcal{L}_\text{aux}=\mathcal{L}_\text{ins}\left(\mathbf{g}_i^{\mathcal{T}}, \mathcal{H}\left(\mathrm{y}_i\right)\right)
$$
- 여기서 $\mathcal{H}$는 instance information을 targets으로 encode함.
- 다만, 위 식에서 $i$-th instance annotation에 해당하는 $\mathrm{y}_i$를 $\mathbf{g}_i^{\mathcal{T}}$와 $\mathcal{H}\left(\mathrm{y}_i\right)$를 통해서 구할수 있기 때문에 위 식을 바로 사용하면 trivial solution이 됨. 이는 결과적으로, teacher representation $\mathcal{T}$를 무시하고 parameters를 학습하게 될 가능성이 있다는 것을 의미함.
- 이를 해결하기 위해, encoding function $\mathcal{E}(\cdot)$에 대한 정보를 drop하여 aggregation function $\mathcal{F}_\text{agg}$이 $\mathcal{T}$로부터 hint를 얻도록함.
- 이러한 information dropping은 instance condition에 대한 정확한 annotation을 불확실한 것으로 교체하는 것을 의미하는데, bounding box annotations의 경우에는, 아래의 식과 같이 rough box center $\left(x_i', y_i'\right)$와 rough scales indicators $[\log_2(w_i)], [\log_2(h_2)]$를 활용하여 얻을 수 있음.
$$
\left\{\begin{array}{l}
x_i^{\prime}=x_i+\phi_x w_i, \\
y_i^{\prime}=y_i+\phi_y h_i,
\end{array}\right.
$$
- 여기서, $\left(w_i,h_i\right)$는 bounding box의 width와 height를 나타내며, $\phi_x, \phi_y$는 uniform distribution $\Phi \sim U[-3, 3]$에서 샘플된 값을 의미함. 결과적으로 coarse information을 얻어 $\mathcal{E}$를 통해 instance encoding을 얻을 수 있음.
- Aggregated representation $\mathbf{g}_i^\mathcal{T}$는 auxiliary task로 최적화되는 데, 이를 위해 $\mathcal{F}_\text{obj}$와 $\mathcal{F}_\text{reg}$를 각각 도입하여, identification과 localization results를 예측함. 아래의 식과 같이 real-fake identification을 최적화하기 위해 binary cross entropy loss $(\text{BCE})$를, regression을 최적화하기 위해 $L1$ loss를 적용함.
$$
\mathcal{L}_\text{aux}=\mathcal{L}_\text{BCE}\left(\mathcal{F}_\text{obj}\left(\mathbf{g}_i^\mathcal{T}\right),\delta_\text{obj}(\mathrm{y}_i)\right)+\mathcal{L}_{1}\left(\mathcal{F}_\text{reg}\left(\mathbf{g}_i^\mathcal{T}\right),\delta_\text{reg}(\mathrm{y}_i)\right)
$$
- 여기서, $\delta_\text{obj}(\cdot)$은 indicator로서, $\mathrm{y}_i$가 real이면 1을 fake이면 0을 뱉어냄.
Instance-Conditional Distillation
- Conditional knowledge distillation를 하기 위해, student representations의 projected value features $\mathrm{V}_j^\mathcal{S}\in\mathbb{R}^{L\times d}$를 얻고, feature와 각 instance 사이의 correlations을 측정하는 instance-aware attention mask $\mathbf{m}_{ij}$를 사용함으로써, 아래와 같이 distillation loss를 설계할 수 있음.
$$
\mathcal{L}_\text{distill} = \frac{1}{MN_r}\sum^{M}_{j=1}\sum^{N}_{i=1}\delta_\text{obj}(\mathrm{y}_i)\cdot\left<\mathbf{m}_{ij},\mathcal{L}_\text{MSE}\left(\mathrm{V}^\mathcal{S}_j,\mathrm{V}^\mathcal{T}_j\right)\right>
$$
- 여기서, $N_r=\sum^{N}_{i=1}\delta_\text{obj}(\mathrm{y}_i), (N_r\le N)$는 real instance의 수를 나타내고, $\mathcal{L}_\text{MSE}\left(\mathrm{V}_j^\mathcal{S},\mathrm{V}_j^\mathcal{T}\right)\in\mathbb{R}^L$는 pixel-wise mean-square error를 표현하며, $\left<\cdot,\cdot\right>$은 inner product를 위한 Dirac notation임. Supervised learning loss $\mathcal{L}_\text{det}$를 포함하는 전체 loss function은 아래와 같음.
$$
\mathcal{L}_\text{total}=\mathcal{L}_\text{det} + \mathcal{L}_\text{aux}+\lambda\mathcal{L}_\text{distill}
$$
- 여기서, $\mathcal{L}_\text{det}$와 $\mathcal{L}_\text{distill}$에 대한 gradient만 student network로 back-propagation되며 $($student networks를 학습할 때 활용$)$, $\mathcal{L}_\text{aux}$의 gradient는 instance-conditional decoding function $\mathcal{G}$과 auxiliary task와 관련된 modules만을 update함.
Conclusion
- 본 논문은 human observed instances와 연관된 knowledge를 찾고 선택하기 위한 instance-feature cross attention를 활용하는 Instance-Conditional knowledge Distillation $(\text{ICD})$ 를 제안함.
- 본 방법은 instance를 query로, teacher's representation을 key로 encode하며, knowledge를 찾는 방법을 decoder에게 학습하기 위해, auxiliary task를 설계함.
- 제안된 방법은 다양한 detectors에 대해 일관되게 성능을 향상시켰으며, 몇몇 student networks는 teacher networks보다 성능이 뛰어남.