This is a Korean review of
"ScaleKD: Distilling Scale-Aware Knowledge in Small Object Detectors"
presented at CVPR 2023.
TL;DR
- Scale-decoupled feautre distllation module을 통해 teacher의 feature를 multi-scale embedding에 disentangled하여, small object에 대한 학생의 feature mimicking을 용이하게 함.
- Cross-scale assistant를 통해, student에게 부정적인 결과를 초래하는 noisy하고 uninformative한 bounding box prediction을 refine함.
- Multi-scale cross-attention layer를 통해 multi-scale semantic information을 포착함.
Introduction
Challenge for Comlexity-Precision Balance for SOD
- Balance detection quality on small object with computational costs at the inference stage
SOD Limiations
- Noisy feature representations: 작은 물체는 전체 그림에서 일부분만을 차지하기 때문에 작은 물체의 feature representation이 배경이나 다른 물체에 의해 오염될 수 있음.
- Low tolerance for noisy bounding boxes on small objects: Teacher 모델의 부정확한 bounding box 예측으로 인한 small perturbation이 SOD의 성능을 훼손시킬 수 있음.
Methods
Scale-Decoupled Feature $($SDF$)$
- 기존 feature-based KDs에서는 다양한 크기의 물체가 single embedding에 coupling 되어 있음. 이는 student 모델이 small objects's feature를 mimic 하는 것을 어렵게 함.
- SDF aims to decouple a single-scale feature embedding into a multi-scale feature embedding, which is obtained by a parallel multi-branch convolutional block.
Cross-Scale Assistant $($CSA$)$
- Teacher 모델과 student 모델로부터의 representations을 single feature embedding에 mapping 하는 multi-scale cross-attention module을 통해 fine-grained 하고 low-level details를 보존함.
Experiments
- Two-stage detectors, anchor-based detectors, anchor-free detectors를 포함하는 다양한 형태의 detectors를 활용해 COCO와 VisDrone 데이터셋에 대해서 해당 방법의 성능을 검증함.
- Detection뿐만 아니라 instance segmentation, keypoint detection에서도 적용함.
Related Work
Knowledge Distillation
Small Object Detection
Scale-aware Knowledge Distillation

- 작은 물체 탐지에서, SOD에 대한 성능을 향상하기 위해 high-resolution image를 input으로 활용함.
- 본 논문에서는 teacher 모델에 high-resolution image를 student 모델에 standard-resolution image를 사용함.
Scale-Decoupled Feature Distillation
Preliminary
- 일반적인 물체 탐지 기법들은 FPN을 활용해서 multi-scale semantic information을 얻음.
- Teacher의 feature정보를 student에게 전달하기 위해 다음의 distillation loss를 활용함.
$$ \mathcal{L}_{\text {feat }}=l\left(\mathcal {F}^T, f\left(\mathcal {F}^S\right)\right) $$
Motivation
- 기존의 물체탐지 KD는 다양한 사이즈의 물체를 distillation 과정에서 동일하게 처리함. 즉, 이는 다양한 물체들에 대한 feature representations을 entangled하고, 배경이나 큰 물체가 작은 물체의 feature representation을 오염되게 함.
- Teacher의 feature map을 disentangled 하기 위해 Scale-Decoupled Feature $($SDF$)$ 를 제안함.
Method
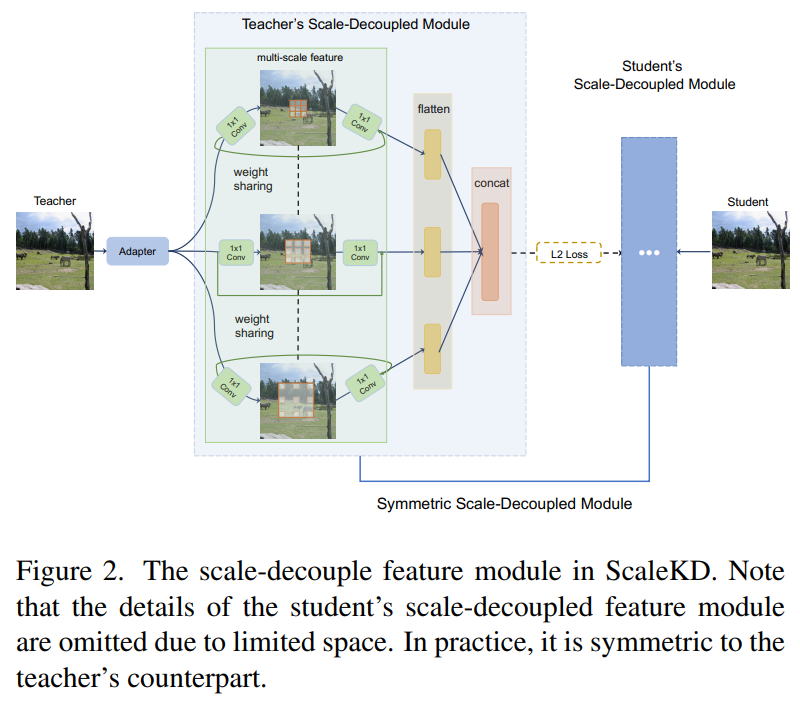
- Teacher object detector의 전체 feature represnetation를 multiple parts로 나누며, 각각의 part는 similar object size를 다룸. 이를 통해 student가 전체 이미지의 global knowledge뿐만 아니라 scale-specific knowledge도 이해하게 함.
- Teacher와 student backbone모델의 마지막 stage로부터 feature embedding $Z^{T}$, $Z^{S}$를 각각 얻음.
- 다양한 input scale에 대한 representation을 완전히 활용하기 위해 multi-branch 구조를 채택함. 각 branch는 서로 다른 dilated rates의 convolutional layer를 사용함. $($작은 dilated rate는 small obejct에 foucs, 큰 diated rate는 large obejct에 focus함.$)$
- Teacher와 student 간의 feature dimensionality를 일치시키기 위해 adapter layer $($i.e., MLP$)$를 scale-decoupled feature module전에 적용함.
- Branch가 동일한 operator를 가진다는 사실에 기반해, weight-sharing scale-decoupled feature를 사용함. 이를 통해, training memory cost를 줄일 수 있음.
- 각 branch에 서로 다른 loss를 사용해 teacher와 student의 branch를 일치시키는 것은 불필요한 hyperparameter tuning이 필요함. 따라서, flattened layer $($i.e., MLP$)$를 각 branch에 적용하고 이를 다 함께 concatenate 해서 처리함.
Cross-Scale Assistant
Preliminary
- Teacher의 bounding box 정보를 student에게 전달하기 위해 다음의 regression disillation을 활용할 수 있음.
$$ \mathcal{L}_{\text {bbox }}=l_{\text {bbox }}\left(\mathcal{R}^S, \mathcal{R}^T\right) $$
Motivation
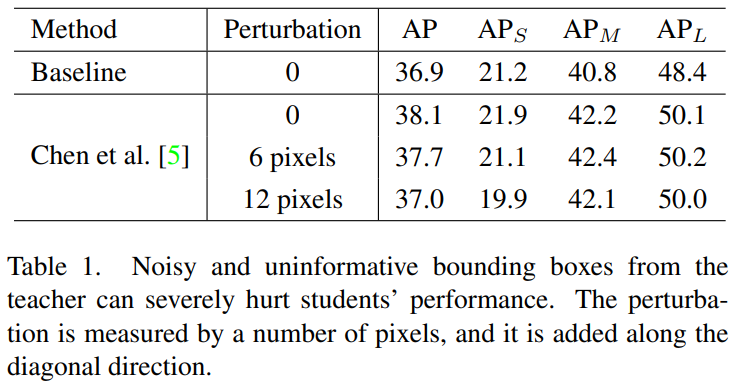
- Teacher detector가 모든 물체에 대해 완벽한 예측을 할 수 없기 때문에 noisy 할 수밖에 없지만, 일반적인 물체탐지와는 다르게, SOD는 noisy bounding boxes에 민감하기 때문에, student에게 혼란을 주어 SOD의 성능을 낮게 만듦.
- Noisy가 small object 성능에 미치는 영향을 확인하기 위해 Table 1의 실험을 진행했으며, 이를 통해 perturbation이 더해졌을 때 student의 small object에 대한 AP가 감소함을 확인할 수 있음.
- 이 결과가 teacher prediction이 완벽해야 함을 의미하는 것이 아니라 $($완벽해야 한다면, ground truth를 활용하면 되지만$)$, teacher의 정보가 학생게게 유익하도록 refine 할 필요가 있다는 것을 의미함.
Method

- Cross attention module을 통해 CSA를 구성할 수 있음. cross attention 과정 동안, teacher knowledge 내의 KQ-attention을 계산하기 위해 key와 query tokens를 생성하고, 이를 student의 output인 value tensor에 mapping 함으로써 feature 내의 attentive regions을 얻음. 유익한 region-based feature를 추출하기 위해 student의 각 pyramid scale에서 수행함.
- 기존의 plain cross-attention은 큰 물체는 focus 하고 작은 물체는 무시하기 때문에, 본 논문에서는 multi-scale cross-attention layer를 새롭게 제안함.
- 가장 responsive 영역을 강조하기 위해 각 query-key pair마다 value를 생성한 후, query-key pair를 multiple sub-paris로 split 함. 여기서, 각 sub-pair는 set of object scale를 나타냄. 이러한 multi-scale query-key는 attention module이 다양한 scale의 region에 집중하도록 함.
- $F^{T}$는 query $Q$와 key $K$로 projection 되고, $F^{S}$는 value $V$로 projection 되며, key와 value는 i로 index 되는 각 head에 따라 서로 다른 크기로 down-sampling 됨. multi-scale cross-attention $($MSC$)$은 다음의 식으로 정리됨.
$$ \begin{gathered} Q_i = F^S W_i^Q, \\ K_i = \operatorname{MSC}\left(F^T, r_i\right) W_i^K, \\ V_i = \operatorname{MSC}\left(F^T, r_i\right) W_i^V, \\ V_i = V_i+P\left(V_i\right) \end{gathered} $$
- $\operatorname{MSC}\left(\cdot, r_i\right)$ is a MLP layer for aggregation in the $i-$th head with the down-sampling rate of $r_i$, $P\left(\cdot\right)$ is a depth-wise convolutional layer for projection.
- multi-scale cross-attention는 일반적인 cross attention보다 SOD에 필요한 fine-grained 하고 low-level details를 더욱 보존할 수 있음. 최종적으로, attention tensor는 다음의 식으로 계산됨.
$$
h_i=\operatorname{Softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_h}} V_i\right)
$$
- CSA의 목적이 teacher와 student 간의 cross-scale 정보를 연결하여 bounding box를 refine 하는 것이기 때문에 classficiation branch와 regression branch에 head layers를 쌓아 learnable module의 weight를 update 했음. $($Adam optimizer with an initional learning rate of 3e-4 and a weight-decay of 1e-4$)$
- Empirical 분석 (in "Impact of Cross-Scale Assistant")을 통해, CSA가 small object에 대해 더 적절한 supervision 함을 보임.
- 이는 learnable moduel이기 때문에, 매 iteration마다 student model 이전에, standard training scheme과 detection objectives를 통해서 weight update 함.
- Teacher의 output을 전달하는 것이 아니라, classification과 regression branch에 대한 CSA 지식을 student에게 전달함.
Total Training Objective
$$
L_{\text {total }}=\alpha L_{\text {feat }}+\beta L_{c l s}+\gamma L_{b b o x}+L_{d e t}
$$
- Student를 최적화하기 위해 distillation loss와 detection loss를 사용할 뿐만 아니라, detection head를 공유하여 instructive representation quality와 student representation과의 consistency를 보장함.
- 무작위로 초기화된 student detector가 CSA 학습의 불안정을 야기할 수 있기 때문에, 30k iteration까지 warm up 함.
Experiment
- 성능 평가를 위해 COCO와 VisDrone dataset을 활용함. COCO는 80개의 class로 구성된 challenging 한 물체 탐지 datasets이고, VisDrone은 drone-shop image에 집중된 dataset이며 대다수의 물체가 작은 물체로 이루어져 있음.
Main Results
COCO

- Two-stage detection $($e.g, Faster-RCNN, Cascade-RCNN$)$, one-stage detection $($e.g., RetinaNet, FCOS, RepPoints$)$ 모두 inference에서 extra computational cost 없이 상당한 성능 개선을 얻음.
- SOD에서의 성능뿐만 아니라, 일반적인 AP 성능도 향상됨.
VisDrone

- VisDrone은 대부분 작은 물체로 이루어진 dataset이기 때문에 SOD에 대한 효과성을 검증하기에 타당하며, ScaleKD를 적용했을 때 성능이 향상됨을 확인할 수 있음.
Results on other instance-levels tasks with small input resolution
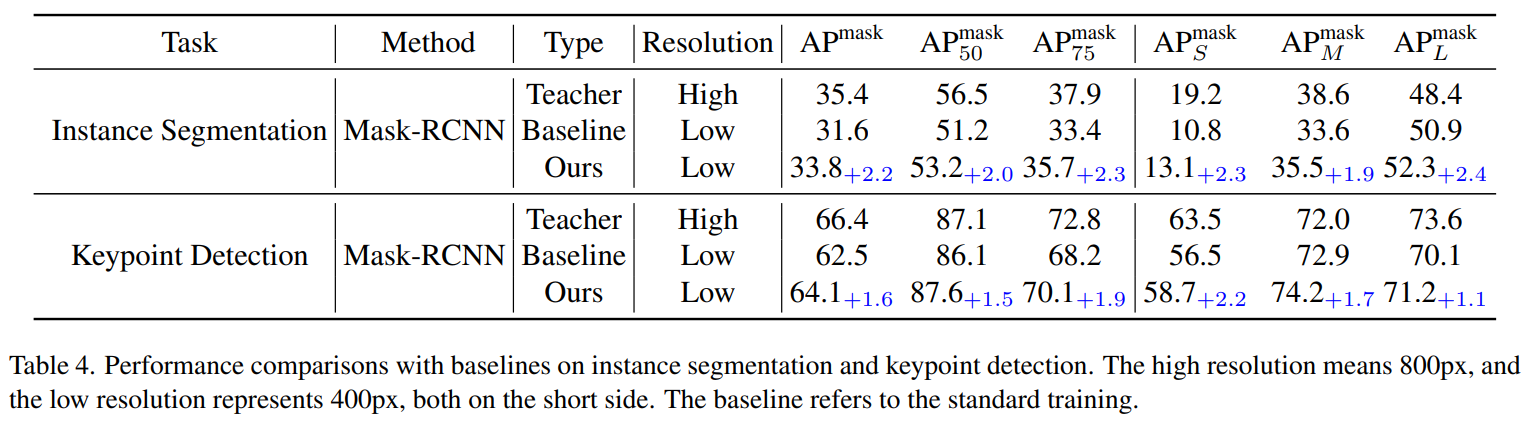
- Input resolution은 SOD에서의 좋은 성능을 얻기 위해 중요한 요소임. 일반적으로 input resolution이 낮으면, 상당한 성능 하락이 나타남.
- ScaleKD를 적용하면, instance segmentation과 keypoint detection tasks에서 small input resolution에서도 baseline보다 높은 성능을 기록함.
Ablation Study
Comparison with SOTA KD

- 공정한 비교를 위해, teacher에 대해서도 standard image resolution을 사용하여 모든 방법에 대해서 teacher performance가 동일하도록 했음.
- ScaleKD achieves superior performance on most evaluation metrics.
Impact of Cross-Scale Assistant
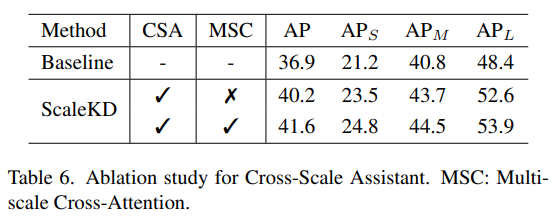
- Teacher에도 standard image resolution를 사용하여 CSA와 MSC의 효과성을 확인했음. 각 요소가 성능 개선에 도움이 된다는 것을 보임.
Ablation study of Scale-Decoupled Feature

- Teacher에도 standard image resolution을 사용하여 SDF module에 대한 ablation study를 진행했음. SDF가 성능개선에 도움이 된다는 것을 확인했으며, separate weight가 큰 성능향상을 가져오지 못한다는 것을 통해 weight-sharing module이 momory cost를 save 하는 데 가치 있다는 것을 보임.
Scale KD for diverse model complexity
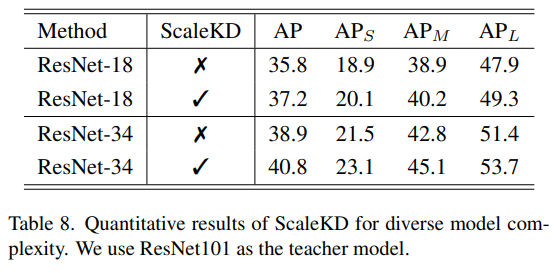
- 해당 실험을 통해, ScaleKD가 다양한 모델 사이즈에서도 효과적임을 확인함.
Discussion
- Inference speed와 detection performance 간의 balance를 위해 본 논문에서는 ScaleKD를 제안함. 이는 multi-scale features를 decouple 하는 scale-decoupled feature distllation과 more informative knowledge를 위해 teacher의 bounding box noise를 refine 하는 cross-scale assistant를 포함함. COCO와 VisDrone에 대해서 성능개선 효과를 입증함.