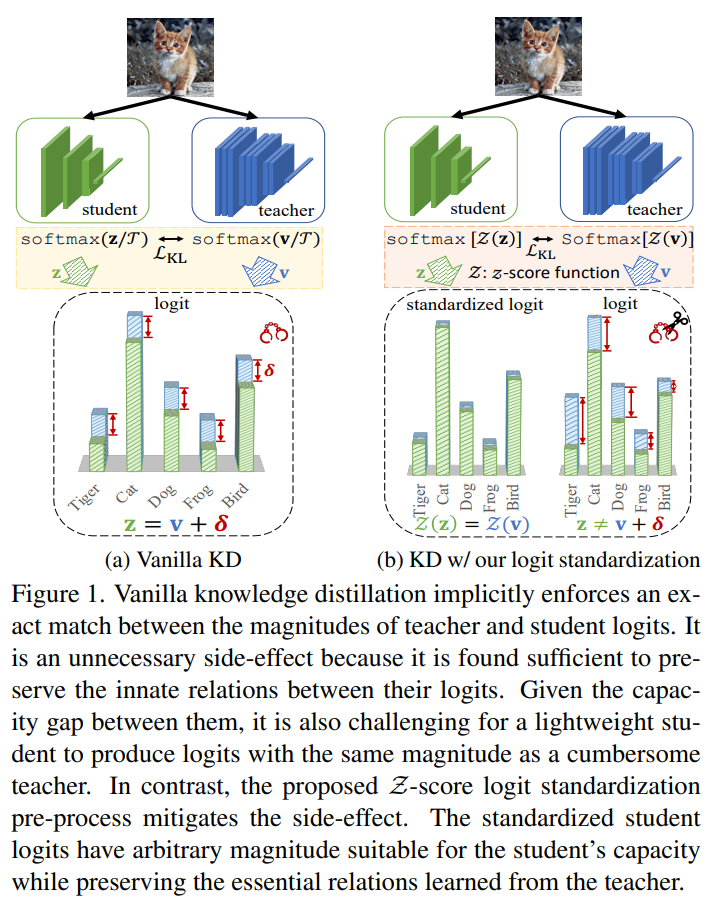
This is a Korean review of"Logit Standardization in Knowledge Distillation"presented at CVPR 2024.TL;DRKD에서 teacher와 student의 soft label $($i.e., prediction$)$을 얻을 때 사용하는 shared temperature은 teacher와 student logits의 range와 variance의 mandatory exact match를 전제로 함. $($in fact, relation is important.$)$기존 방법의 한계를 극복하기 위해, adaptive temperature로 weighted logit standard deviation을 사용함.이를 활용해, softmax를 ..