This is a Korean review of
"Logit Standardization in Knowledge Distillation"
presented at CVPR 2024.
TL;DR
- KD에서 teacher와 student의 soft label
- 기존 방법의 한계를 극복하기 위해, adaptive temperature로 weighted logit standard deviation을 사용함.
- 이를 활용해, softmax를 적용하기 전,
Expression Transformation
| Student prediction | |
| Convential Form |
|
| Constrained Entropy-Maximization Form |
|
| General Form |
|
| Logit Standardization |
Introduction

- 본 논문은 classification과 KD에서 사용되는 softmax가 정보이론의 entropy maximization 원리에서 유도됨을 보이는데, 이 과정에서 temperature가 Lagrangian multiplier로부터 얻을 수 있음을 보임.
- 이를 바탕으로, teacher와 student의 temperature 간의 무관성
- Teacher와의 capacity gap으로 인해 teacher와 유사한 range와 variance를 가지는 logit을 예측하는 것이 어려운데, 이를 극복하기 위해 adaptive temperature로서 weighted logit standard deviation을 사용하며,
Related Work
- 예측된 확률분포를 smooth 하게 만들기 위해 적용되는 temperature
- CTKD는 adversarial learning을 적용해 sample 난이도에 따른 sample별 temperature를 활용했지만, teacher와 student가 동일한 temperature를 공유해야 한다고 가정함.
- ATKD [paper to read]가 sharpness metric을 제안하고, adaptive temperature를 적용했지만, zero logit mean이라는 ATKD의 가정은 numerial apporximiation에 의존함.
- 이전 연구를 통해, student와 teacher 간의 exact logits matcing 대신, prediction의 inter-class relation만으로도 충분하지만, 기존의 sharing temperature 적용은 여전히 implicit 하게 exact mathcing 하도록 만듦.
Background and Notation
- Student's logit은
- Temperature
- Knowledge distillation은 아래의 KL divergence를 최소화하여
- 이론적으로
→ teacher prediction는 학습 동안에 고정된 값이고, student prediction을 최적화하는 과정이기 때문에,
→
Method
1) Irrelevance between Temperatures
- KD와 classification에서의 temperature-involved softmax를 entropy-maximization principle를 통해 유도함. 이는 student와 teacher 간의, sample 간의 서로 다른 temperature 적용 가능성을 시사함.
Derivation of softmax in Classification
- 첫 번째 제한조건은 discrete probability density 조건으로, 확률 분포 정의에 따라 합이 1이 되어야 함.
- 두 번째 제한조건은 기댓값이 목표 클래스
- Lagrangian multipliers
- 미분값에 0을 취하면 solution을 얻을 수 있음.
Derviation of softmax in KD
- Constrained entropy-maximization optimization는 아래와 같음.
- 첫 번째와 두 번째 제한조건은 classification과 동일함.
- 세 번째 제한조건은, KD에 의해 student가 완전히 학습되었다고 가정하면 teacher logit과 student logit이 동일해야 하기 때문에 추가됨.
- Lagrangian multipliers
∴ Distinct Temperature
- 각 constraints는
- 따라서,
∴ Sample-wisely different Temperature
- 일반적으로 모든 샘플에 대해서 global temperature를 정의하지만
2) Drawbacks of Shared Temperature
- Entropy-maximization으로부터 유도한 식을, hyper-parameters
- 이상적으로 학생이 완전한 정보를 전달받았다고 하면, KL divergence loss는 minimum에 도달하고, student의 확률분포는 teacher와 일치하게 됨. 즉,
- 위의 식을 제곱하여
- 위의 식을 통해서, well-distilled student의 특성을 ① logit shift와 ② variance matching으로 나타낼 수 있음.
① Logit shift
- 기존의 shared temperature를 적용
- 하지만, 두 모델의 capacity 차이를 생각할 때, student는 teacher처럼 넓은 logit range를 얻을 수 없음.
- 정확한 logit matching보다 logit rank만을 유지하면 되기 때문에, 기존 KD방법의 logit shift는 student에게 불필요한 어려움을 제공함.
② Variance match
- 위 식은 temperature ratio와 standard deviation ratio가 동일함을 의미함. 기존 shared temperature
3) Logit Standardization


- 기존 shared temperature가 가지는 logit shift, variance match의 두 가지 단점을 극복하기 위해,
① Zero mean
② Finite standard deviation
- Weighted
- Standardized student와 teacher logit을 zero mean과 definite standard deviation을 가지는 Gaussian-like 분포로 표현가능함.
- Standardization의 mapping은 many-to-one이기 때문에 그 반대는 정의되지 않음. 즉, 기존 student logit vector의 variacne와 value range는 제한 없음.
③ Monotonicity
- Teacher logit 내의 필수적인 고유 관계가 보존됨.
④ Boundedness
- Standardized logit은
Toy Case
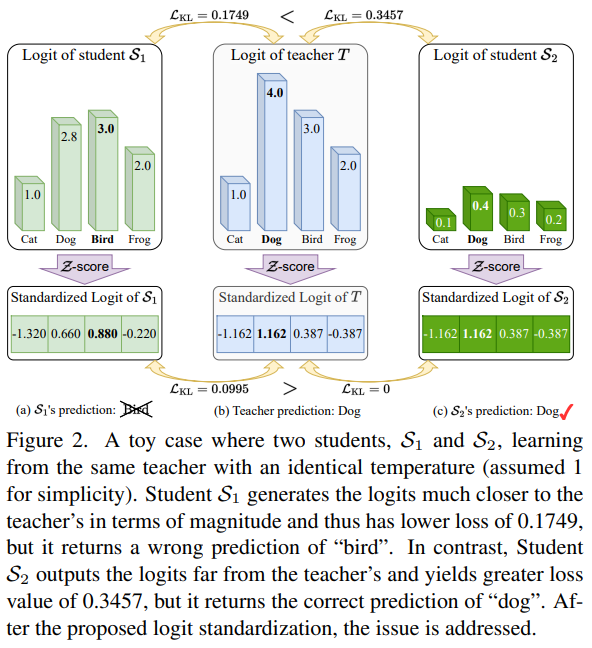
Experiments
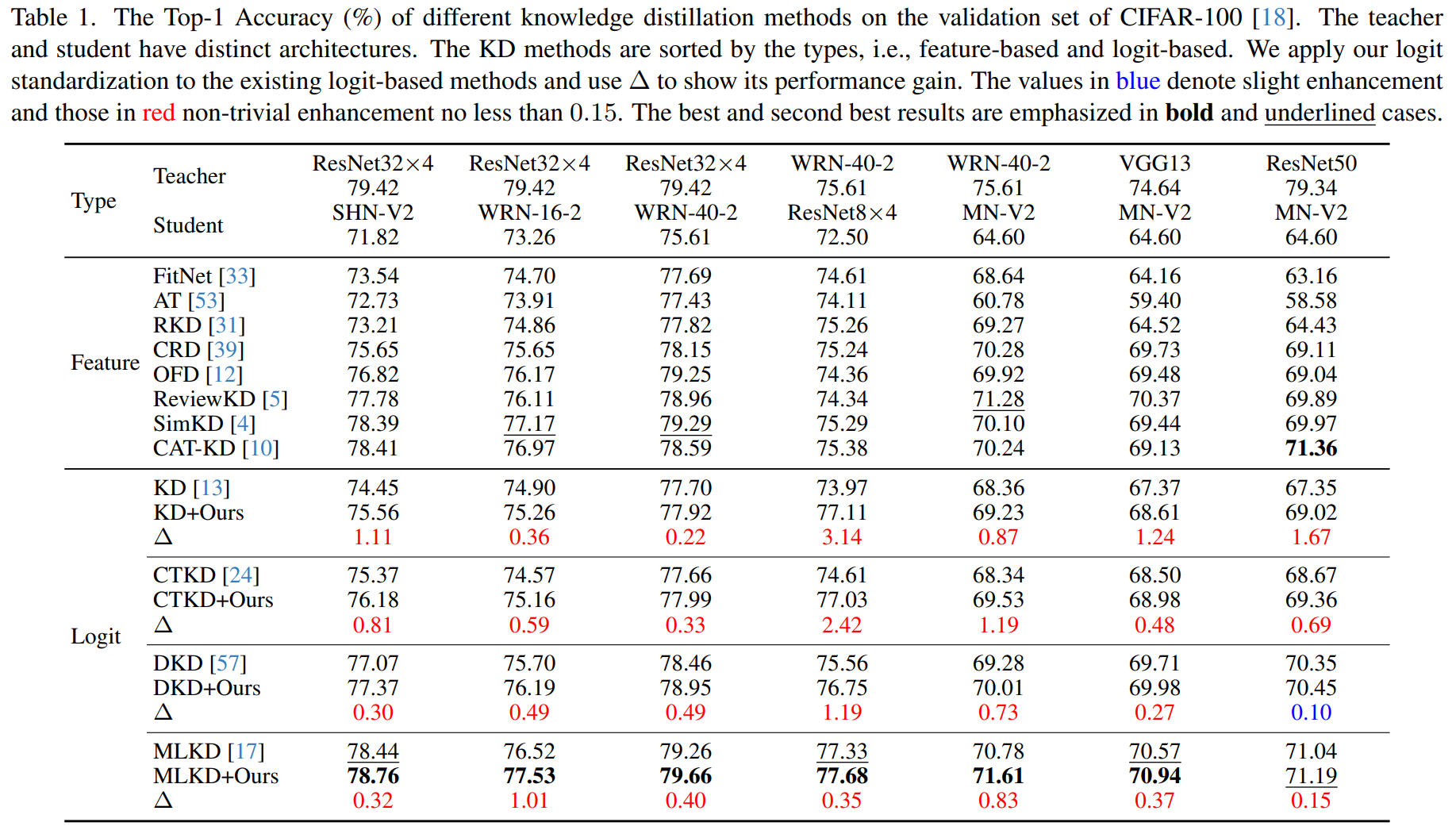
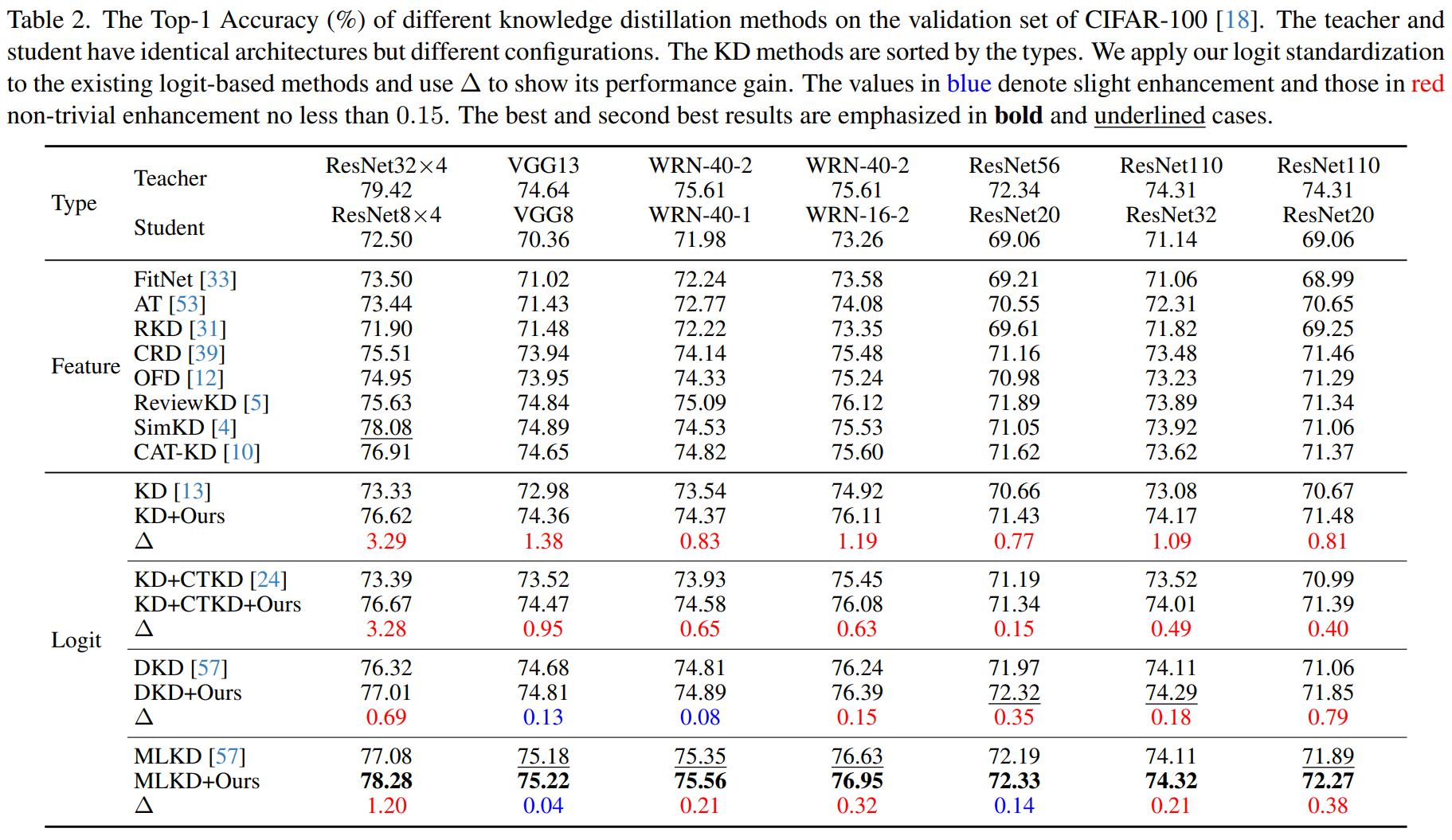
Main Results
CIFAR-100
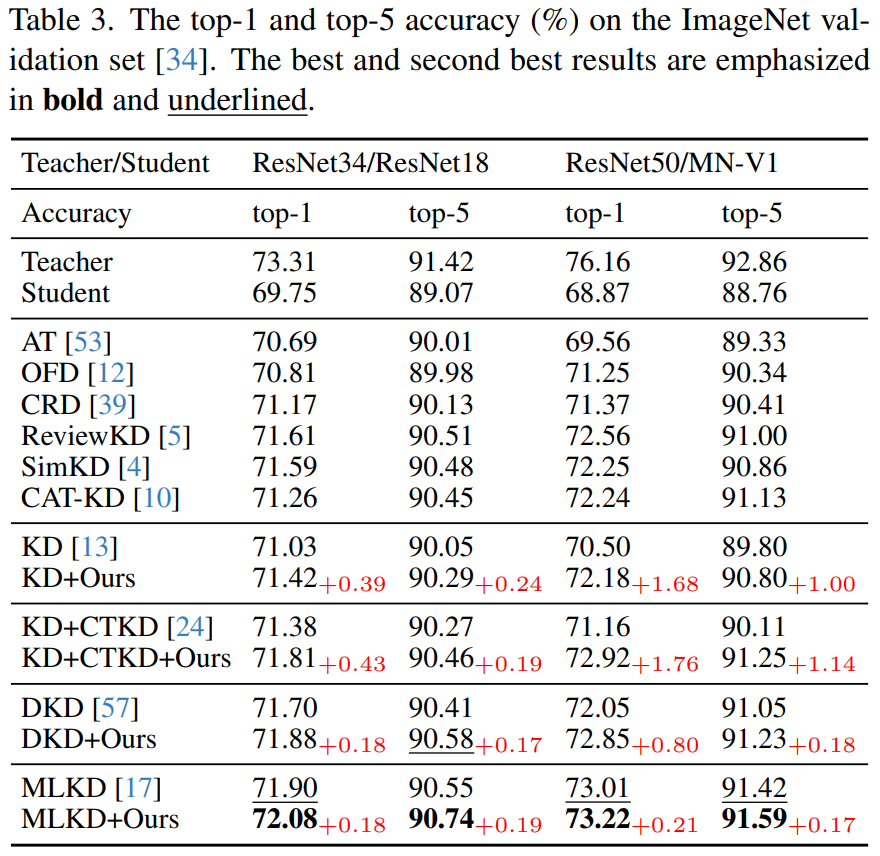
ImageNet
Ablation Study
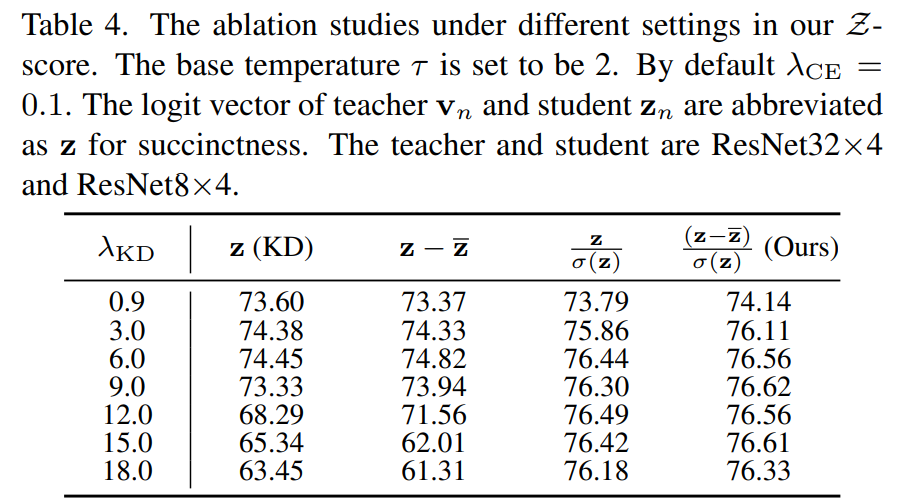
- KD loss의 weight가 증가할수록, vanilla KD의 성능은 급격히 하락하는 것에 반해,
Extensions
Logit range
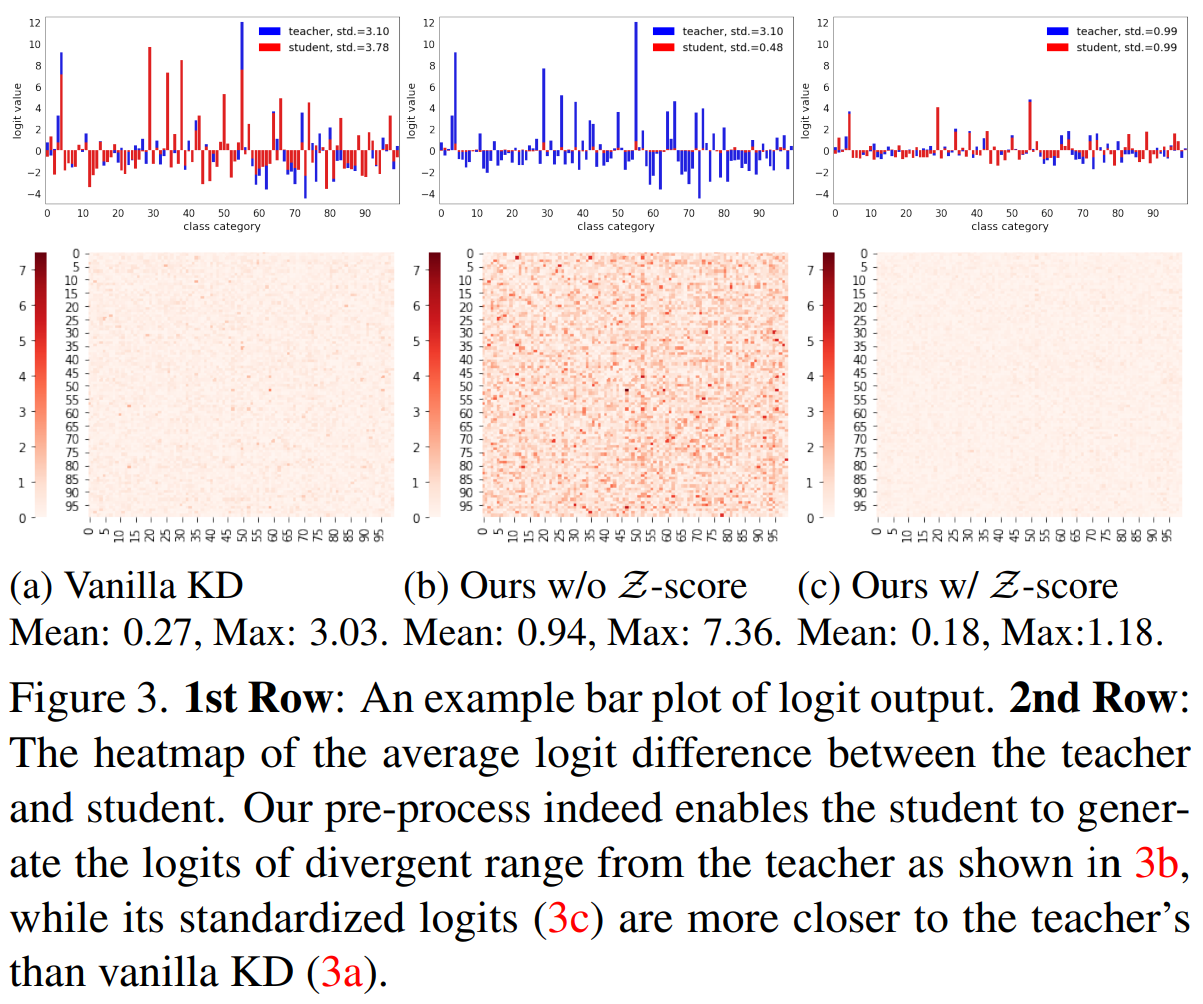
- 기존 KD를 적용하면, target index에 대해서 student가 teacher만큼의 large logit을 가질 수 없는 반면, 본 논문에서의 방법을 적용하면, 적절한 range의 logit을 만들어 teacher을 잘 모사하도록 함.
Logit variance
- 기존 KD는 student logit의 variance가 teacher의 variance로 접근하도록 하지만, 본 논문 방식은 student logit이 flexible logit variance를 가지도록 함. standardized logit은 teacher와 동일한 variance를 가짐.
Feature visualizations

Improving distillation for large teacher
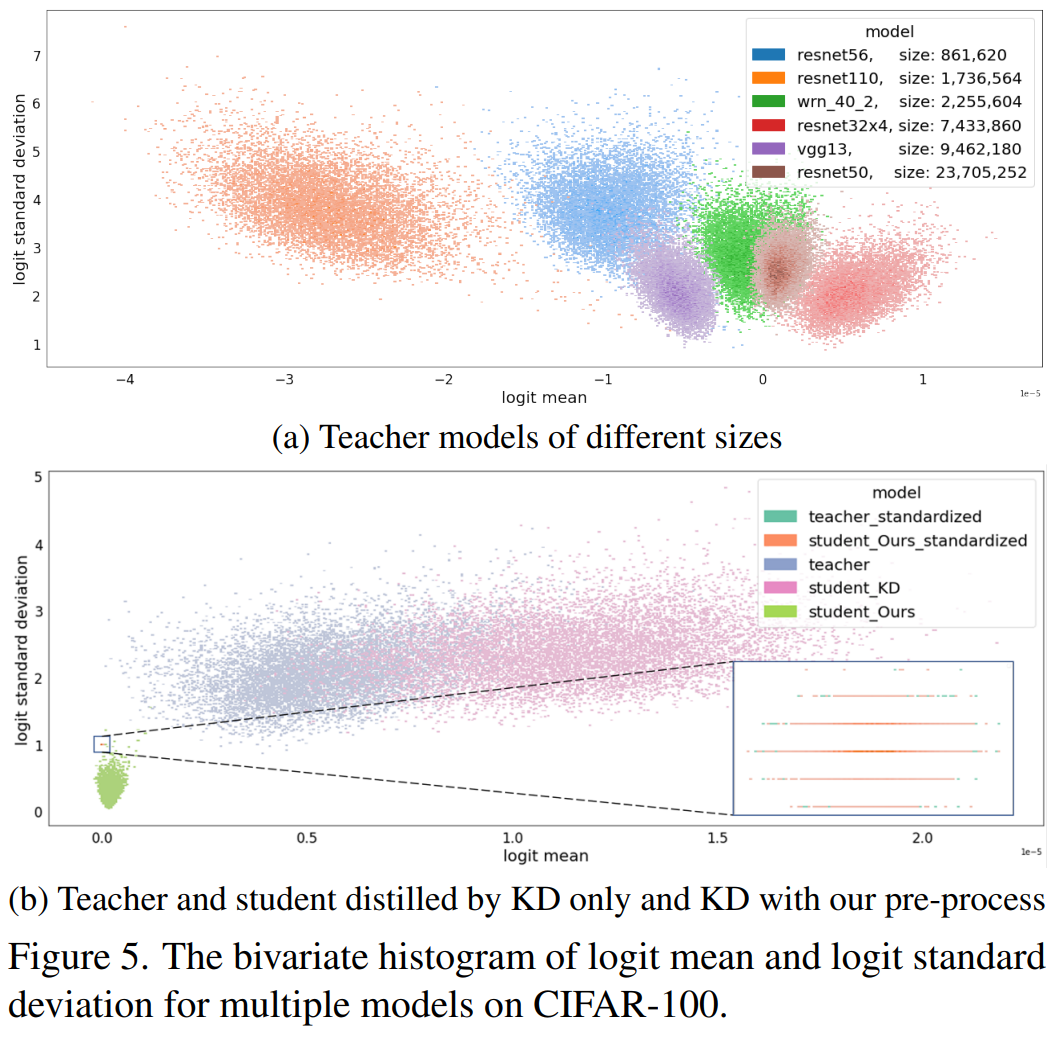
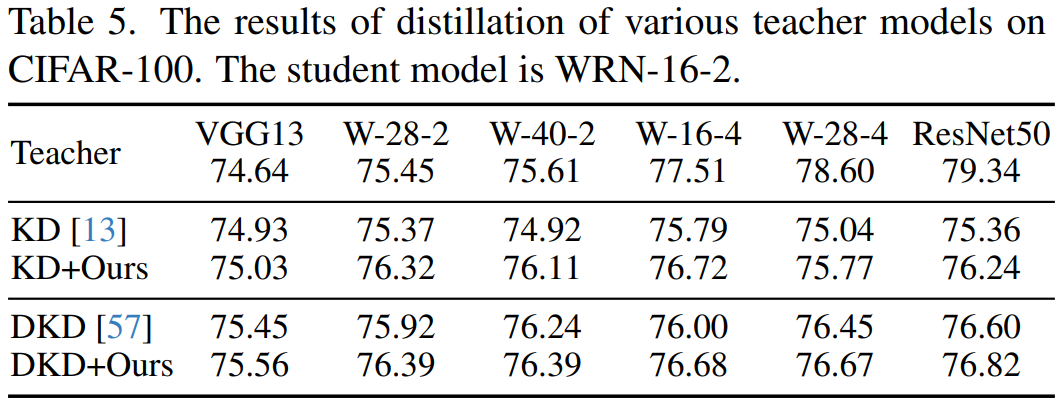
- 큰 teacher가 언제나 좋은 teacher를 의미하는 것이 아니며, 이는 teacher와 student 간의 capacity gap으로부터 기인한다고 설명되어 옴.
- 본 논문에서는 이를 student가 teacher와 동일한 logit range와 variance를 모사하기 어렵기 때문이라고 해석하고 이를 시각적으로 확인하고자 그림 5를 얻음.
- 그림 5를 보면, 큰 model
- 따라서, 작은 model인 student가 큰 model인 teacher 만큼 compact logit을 얻는 것은 어려움.
- 그림 5 b를 통해서, student의 모방 능력을 비교할 수 있음. logit mean과 standard deviation에 대해서 vanilla KD는 teacher와 상당 부분 떨어진 logit을 만들어내는 반면, standardized logit mean과 standard deviation에 대해, 제안 방법은 완전한 일치를 보여줌.
Conclusions
- Conventional KD에서 global 하고 shared temperature를 사용하는 이론적 근거가 없었기 때문에, entropy maximization을 사용하여, temperature가 Lagrangian multiplier으로부터 유도됨을 보였고, 이를 통해 constant temperature대신 flexible value를 할당할 수 있음을 증명함. 이를 기반으로