This is a Korean review of "What Makes a Good Dataset for Knowledge Distillation?" presented at CVPR 2025.
TL;DR
- 일반적인 KD는 학생 모델을 학습할 때, 선생 모델이 학습한 원본 데이터셋을 사용할 수 있다는 가정이 있지만, 실제 application에서는 항상 가능한 것이 아님.
- 이를 극복하기 위해, 'supplemental data'를 사용하는 것을 고려할 수 있음. 그렇다면, 어떤 데이터셋이 지식을 전달할 때에 좋은 데이터셋일까?
- Real하고, In-domain dataset 만이 유일한 방법이라고 생각할 수 있지만, 본 연구를 통해, unnatural synthetic dataset도 대안이 될 수 있음을 보임.
Introduction
- 일반적으로, 지식 증류를 수행할 때 선생 모델을 학습할 때 활용한 데이터셋을 사용하지만, 원본 데이터에 항상 접근 가능하다는 가정은 실제 환경에서 타당하지 않음.
- 이러한 한계를 극복하기 위해, 다음의 supplemental data를 사용하는 것을 고려할 수 있음.
- real in-domain examples
- real out-of-domain examples
- synthetic examples opimized to be ID
- unoptimized unnatural synthetic OOD imagery (e.g. OpenGL shaders)
- 일반적으로 real ID가 괜찮은 대안 데이터셋으로 생각되지만, most unconventional dataset을 통해서도 지식이 전달되는 것이 가능할까? → 지식 증류를 위한 데이터셋은 어떤 점이 필요하고,어떤 조건을 만족해야할까?
- 본 논문을 통해서,
- 성공적인 지식 증류를 가능하게 하는 데이터셋의 핵심 특징을 확인하고,
- unnatural synthetic OOD data를 사용해도 성공적으로 지식증류가 가능함을 보임.
- 또한, adversarial attack 전략을 통해서, 이러한 지식 전달을 향상시킴.
Related Work
Knoweldge Distillation
- [1]: KD를 function matching의 시각으로 다루며, 강한 mixup을 적용한 것이 학생 성능을 향상시킨다는 것을 보여줌.
- [2, 3]: Adversarial examples이 선생모델의 decision boundary를 확인하게 만들어 성능 향상에 도움이 됨을 보여줌.
Utilizing Supplemental Data in Knowledge Distillation
- 원본 데이터셋에 접근하지 못할 때, 대체 데이터셋을 활용하는 다양한 연구들이 있음. 그 중에서, [4, 5]은 KD와 domain adaptation을 결합하여, 완전히 다른 도메인(real images↔ drawings)에서 학생 모델이 선생모델과 동일한 클래스를 가지도록 학습함,
Data-Free Knowledge Distillation
- DFKD는 KD에 도움이 되는 데이터를 만들기 위해, 1) generator network를 활용하거나 2) 내제된 선생모델의 statistics를 활용함.
Methodology
Natural Dataset Collection
- 원본 데이터셋과 가장 많은 클래스 정보를 공유하는 데이터셋(e.g., ID)을 대체 데이터셋으로 선택하는 것이 타당하긴 하지만, ID여야만 해야할까? OOD는 활용할 수 없을까?
- 이를 확인하기 위해 CIFAR10, CIFAR100, TinyImageNet, ImageNet (split into ID and OOD subsets), FGVC-Aircraft, Pets, Food, EuroSAT을 활용함.
Synthetic Dataset Collection
- ID 또는 OOD 데이터셋에서 더 나아가, 대체 데이터셋은 Real 이여야 할까? 기존 DFKD 연구들은 이미지 ID에 최적화된 합성 데이터셋 (Unnatural Iamges)를 고려했음. 하지만, 이러한 최적화가 정말로 필요할까?
- 최적화되지 않고, 비자연스러운 OOD 합성 이미지를 사용하여 지식이 전달되는 지 확인하기 위해, OpenGL shaders, Leaves, Noise를 활용함.

- $\mathcal{C}=\{c_1, \dots, c_R\}$ 클래스를 가진 데이터셋에 pretrain된 선생 모델 $\mathcal{F}_T$와 초기 합성 데이터셋 $\mathcal{D}_S$가 있을 때, 각 샘플을 선생모델에 통과시켜 예측값을 얻고, 이를 활용하여 KD에 사용할 최종 합성 데이터셋 $\mathcal{D}_K$를 얻음.
- Teacher에 의해 클래스 $c_i$로 예측된 이미지에 대해서 무작위로 $N_i$개의 샘플을 추출함.
- 만약 특정 예측 클래스가 0이라면, 이를 Skip하고 다른 클래스에서 더 많은 샘플을 추출함.
- 특정 클래스가 $N_i$보다 더 적게 예측되었다면, 해당 갯수를 채우기 위해 복제를 함.
Data Augmentation
- 합성데이터는 필요하다면, 거의 무한에 가까운 데이터를 얻을 수 있지만, 큰 저장용량이 필요할뿐만 아니라, 새로운 합성 샘플들이 이미 존재하는 샘플들과 상당히 다른 샘플이라고 보장하지 않음.
- 따라서, 데이터셋의 다양성을 증가시키기 위한 방법으로, 데이터 증강을 사용할 수 있음. 데이터 증강은 증류 중에 더 많은 샘플들을 만들 수 있을 뿐만 아니라, 선생 모델의 feature space을 더 탐험할 수 있도록 함.
- 일반적인 지도학습에서 데이터 증강은 label-preserving 해야 하지만, KD를 function matching으로 생각하면, 라벨을 더이상 생각하지 않아도 됨. 따라서, 일반적인 지도학습에서는 고려하지 않는 다양한 데이터 증강을 적용할 수 있음.
Knowledge Distillation
Experiments
Datasets & Networks
- Teacher을 학습시키기 위해, general purpose dataset (e.g., C10, C100, Tiny)과 fine-grained/domain-specific dataset (e.g., FGVA, Pets, EuroSAT)을 활용하고, distillation dataset으로는 이 6가지와 더불어, ImageNet-ID, ImageNet-OOD, Food, OpenGL shaders, Leaves, Noise를 사용함.
- CIFAR10/100 trained teacher: ResNet50 → ResNet18 / WRN-40-2; Others: ResNet50 → ResNet18 / MV2
Training Details
- Teacher: Data augmentation으로 RandAugment $(n=2, m=14)$, random horizontal flipping, random copping with padding을 사용함.
- Distillation: Real 샘플의 경우, Teacher 모델을 학습할 때와 동일한 data augmentation을 사용하고, 합성 샘플의 경우, 더 강한 data augmentation인 RandAugment $(n=4, m=14)$, random elastic, random inversion transforms을 추가로 적용함.
Results

Standard Knowledge Distillation
Does the distillation data need to be in-domain?
- 기존 데이터셋을 사용하는 것이 가장 뛰어난 성능을 기록하지만, 많은 real ID 와 OOD surrogate 데이터셋도 어느정도 뛰어난 성능을 기록함.
- Pets으로 학습된 teacher 결과에서는 surrogate (IN-ID, 50K samples)가 기존 데이터셋 (Pets, 3600 samples)보다 뛰어난 성능을 기록하며, FGVCA 데이터셋에서는 IN-OOD (50K samples)가 IN-ID (3900 samples)보다 뛰어난 성능을 기록함.
- 학생을 더 길게 학습하면, alternative OOD 데이터셋을 사용해도 괜찮은 성능을 얻을 수 있지만, ID 데이터가 더 적은 샘플로도 선생 정보를 충분히 학습할 수 있음 (sample efficiency ↑).
Does the distillation data need to be real?
- 비자연스러운 합성 데이터셋을 활용함에도 불구하고, 지식증류가 어느정도 성공적으로 수행됨을 확인할 수 있음.
- 다만, TinyImageNet 처럼 클래스의 수가 커지거나, FGVCA와 Pets 처럼 클래스가 더 fine-grained 하게 되면, 합성데이터셋은 더이상 좋은 성능을 내지 못함.
- Leaves가 noise 보다 더 나은 성능 개선을 보여주는데, 이는 Leaves 이미지에 포함되어 있는 primitive 특성(lines and corners)으로 인한 것으로 생각되며, OpenGL shaders는 Leaves에 비해 더많은 다양성과 texture를 포함하고 있기 때문에 더 큰 성능 개선을 보여줌.
- 즉, 데이터셋이 꼭 실제일 필요는 없으며, 비자연스러운 합성 데이터셋을 사용해도 지식을 충분히 전달할 수 있음.
How does the teacher architecture influence what distillation datasets are viable?
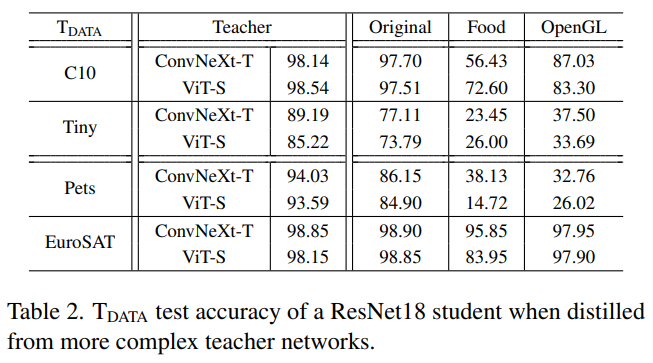
- Teacher의 구조는 KD의 속도에 큰 영향을 미침. 즉, Teahcer가 구조적으로 더 복잡하고 높은 성능을 내는 모델이라면 patient distillation [1]가 요구됨. 하지만, Teacher의 구조가 지식증류를 위한 특정 데이터셋 사용 가능성에 영향을 미치지 않는 것으로 보임.
What Influences Successful Distillation?

- 어떤 요소가 특정 데이터셋이 다른 데이터셋보다 더 뛰어난 성능을 만들게 하는지를 분석하기 위해, Teacher 모델이 각 클래스를 얼마나 예측했는지(class prediction histogram)로부터 relative entropy를 계산함.
- 가장 좋은 성능을 기록하는 데이터셋일수록 relative entropy가 1에 가까우며, 이는 teacher 모델이 모든 클래스를 균일하게 예측한다는 것을 의미함.
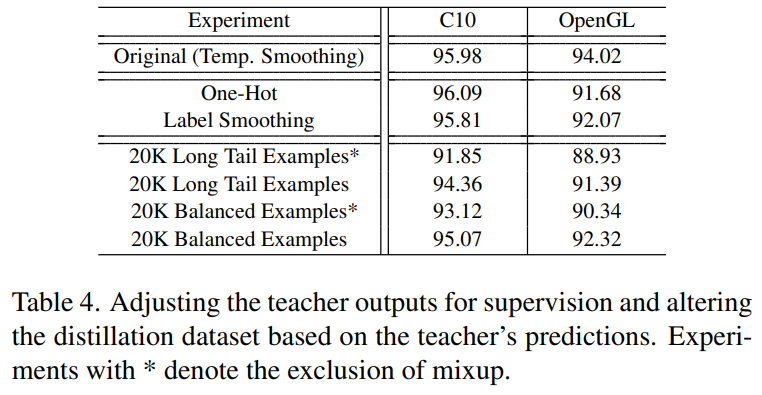
- OpenGL shader image를 활용할 때는, temperature-scaled softmax outputs을 사용하는 것이 one-hot 또는 label smoothing보다 더 높은 성능을 기록함.
- 이는 OpenGL과 같은 OOD data를 사용하여 증류를 할때는, nearby decision boundaries와 클래스간의 관계를 이해하는 것이 특히 중요하다는 것을 보여줌.
- Mixup을 사용하면, Long tail과 balanced 실험에서 성능차이가 미비함. 즉, teacher 모델 예측이 균일하지 않아도 어느정도 괜찮음. 이는 raw sample의 수와 품질이 부적절할 때, mixup을 통해 teacher feature space의 많은 부분을 커버할 수 있기 때문임.

- 과도한 데이터 증강을 사용하면, CIFAR10이 OOD 데이터셋 성능과 유사하게 됨.
- Tables 3-5를 통해서, KD is a task of function matching and sufficient sampling of the teacher.
- 하지만, 모덴 데이터셋이 동일 수준의 샘플링 효율성을 보이는 것은 아님. ID 데이터는 OOD 데이터보다 더 나은 샘플 효율성을 보이며, 원본 데이터가 모든 데이터 중에서 가장 높은 샘플 효율성을 가짐.
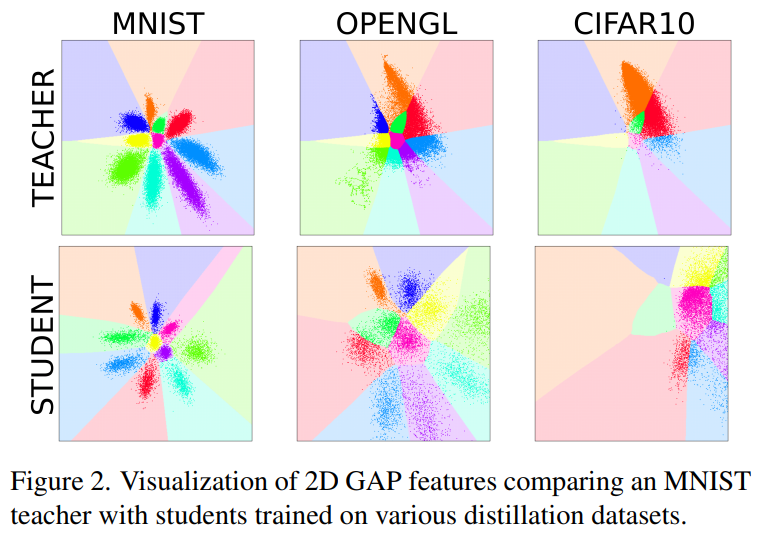
- OpenGL shader 데이터셋은 교사의 모든 클래스 영역에서 예측된 샘플을 가지고 있는 (1에 가까운 relative entropy) 반면, CIFAR10 데이터는 클래스의 일부만 커버함 (0에 가까운 relative entropy).
- 즉, OpenGL shader student는 MNIST student와 유사한 decision boundaries를 얻어 CIFAR10보다 더 높은 성능을 기록함.
Adding Teacher Exploitation
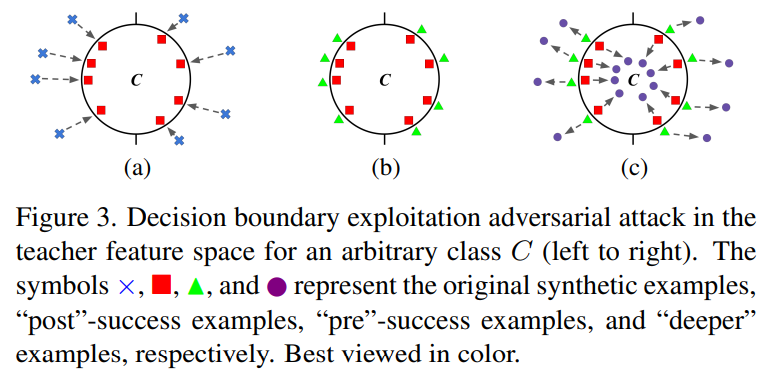

- Surrogate data를 사용하여 지식증류를 할때, decision boudnary information이 KD에 영향을 미침. 즉, 만약 특정 데이터셋이 KD에 좋지 않다면, adversarial attacks을 통해서 샘플의 minor perturbations을 넣어 이를 극복할 수 있음.
- Adversarial attack을 통해서 decision boundary aware dataset을 만들 수 있고, 이를 통해 전체적으로 더 높은 성능을 얻을 수 있음.
Comparisons to Other Data Sources

- 상당한 computational overhead가 필요한 generator network가 없어도, 충분한 성능을 얻을 수 있음.
Conclusion
- KD is a sufficient sampling problem that requires the teacher’s outputs and decision spaces be equally and thoroughly explored.
- It is actually possible to distill many different teacher models using unnatural synthetic imagery in the form of OpenGL shader images.
- Adversarial perturbation strategy that can improve the knowledge transfer was proposed.