This is a Korean Review of "Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions" published in IEEE Access
Taxonomy and Background
- Image 데이터는 일반적으로 RGB 3개의 Channel로 이루어져 있으며, Height × Width × Channel의 차원으로 표현됨.

- Data Augmentation은 Basic Image Data Augmentation과 Advanced Image Data Augmentation으로 분류할 수 있음.
- Basic은 Data Augmentation를 위한 기초적인 기술을 다루며, Advanced는 더욱 복잡한 기술을 다룸.
2. Advanced Image Data Augmentation
2.1. Image Mixing
: 동일 이미지를 포함하여, 하나 이상의 이미지를 Blending하는 방법
2.1.1. Sinlge Image Mixing Data Augmentation
: 단일 이미지 내에서 다양한 혼합 방식으로 증강하는 방법
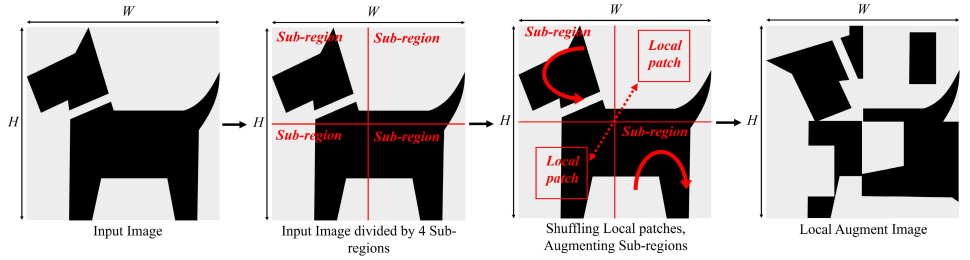
- Local Augment: 이미지를 더 작은 Patch로 나누고 각 Patch에 서로 다른 유형의 데이터 증강을 적용하는 방식으로, 이미지의 개별 Patch를 무작위로 수정하기 때문에, 전체 이미지를 변형하는 Global Augment와는 차별화됨. 이는 이미지의 Global Structure를 보존하진 않지만, Local Feature의 다양성을 증가시킬 수 있음.

- Self-Augmentation: 이미지의 랜덤 영역을 잘라내어 다시 이미지 내에 임의로 붙이는 방법으로, *Few-shot learning의 일반화 성능을 향상시킴. 이 방식은 Regional Dropout(Self-mix)과 Knowledge Distillation을 결합한 방식임.

*Few-shot learning: 소수의 샘플로 학습하는 방법
- SalfMix: 이미지 내에서 어떤 부분을 제거하고 어떤 부분을 복제해야 하는 지 결정하기 위해 이미지의 Salient 부분을 찾고, 가장 Slient 부분을 잘라내어 Non-Salient 부분에 옮기는 방식임.

- KeepAugment: 모델의 성능을 저하시킬 수 있는 Distribution Shift를 방지하기 위해, 이미지지의 Salient Feature은 보전하고 Non-Salient 부분만 증강하는 방법임.

- You Only Cut Once: 이미지를 두개의 조각으로 분할하고, 각 조각에 개별적으로 데이터 증강을 적용한 뒤, 다시 결합하여 새로운 이미지를 생성하는 방법임. 추가적인 파라미터가 필요하지 않기 때문에 쉽게 적용할 수 있음.

- Cut-Thumbnail: 이미지를 일정한 작은 크기로 Resizing한 후, 원본 이미지의 무작위 영역을 해당 Resized 이미지로 대체하는 방법임. 이를 통해 Network의 Shape 편향을 완화할 수 있고, 원본 이미지를 보존하면서도 Small Resized 이미지 안의 Global도 보존할 수 있음.


2.1.2. Multi-Image Mixing
: 두 개 이상의 이미지를 사용하여 다양한 Mixing 전략을 적용하는 방법
- Smart Augmentation: Generative Network를 사용하여 Target Network에 적합한 증강 방식을 학습하는 방법임.
- 즉, Generative Network A가 직접 데이터 증강 방식을 학습하여 최적의 증강 방법을 생성하고, 증강된 데이터는 Target Network B를 학습시키는 데 사용됨.


- Network A는 같은 클래스 내의 여러 샘플 (e.g., $\text{I}_1, \text{I}_2, \text{I}_3, \dots, \text{I}_k$)을 입력으로 받아 혼합된 새로운 샘플 (e.g., $\text{Out}_1$)을 생성함. 이때 $\mathcal{L}_A$는 생성한 증강 데이터가 원래 클래스와 유사하도록 학습함.
- Network B는 Network A가 생성한 데이터를 학습하며, $\mathcal{L}_B$가 Network A로 Backpropagation되어, Network A는 점점 더 효과적인 증강 데이터를 생성할 수 있음.
- 즉, Generative Network A가 직접 데이터 증강 방식을 학습하여 최적의 증강 방법을 생성하고, 증강된 데이터는 Target Network B를 학습시키는 데 사용됨.
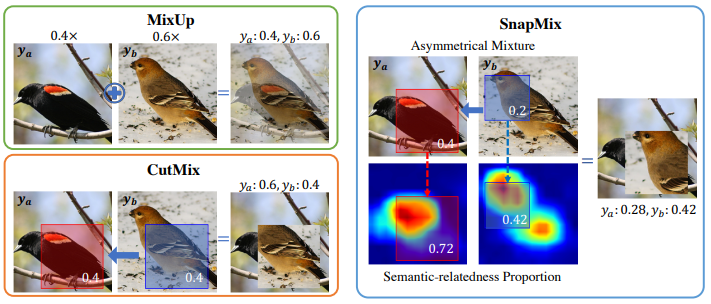
- Mixup: 두 개의 이미지를 $\alpha$로 표현되는 Blending Factor에 따라 혼합하며, Label도 동일한 방식으로 혼합하는 방법
- CutMix: Information Loss와 Region Dropout 문제를 해결하기 위한 증강 기법임. 이미지의 랜덤 부분을 0또는 255로 채우는 cutout과 다르게, 다른 이미지의 Patch로 해당 부분을 채우며, 혼합된 픽셀 수에 비례하여 Label도 혼합됨.


- SaliencyMix: CutMix의 방식이 반드시 의미 있는 정보를 포함한다고 보장할 수 없고, 정보가 부족한 Patch를 혼합하는 것은 불필요한 정보를 학습하게 함. 이러한 문제를 극복하고자, SaliencyMix는 이미지에서 Salient 부분을 선택하고 해당 부분을 다른 이미지의 Salient 또는 Non-Salient 부분에 붙임.


- Random Slices Mixing Data Augmentation (RSMDA): Single Image Erasing 데이터 증강기법에서 발생하는 Feature Losing 문제를 해결하기 위한 방법으로, 한 이미지의 Slices를 추출하고 다른 이미지와 번갈아 가며 혼합함. Label도 동일하게 혼합함. RSMDA는 Row-Wise Slice Mixing (R), Column-Wise Clice Mixing (C), Randomness of Both (RC)의 3가지 방법이 있음.

- Puzzle Mix: Explicitly Salient 정보와 이미지의 Local Statistics를 사용하여 데이터를 혼합하는 증강 기법임.
- Saliency 정보를 활용하여 이미지의 중요한 부분을 결정하고, 이미지의 구조적 일관성을 지키도록 Local Statistics를 유지하며 픽셀 이동을 결정함.

*이미지에서 Local 단위의 픽셀 값들의 통계적 특성을 의미함.
예를 들어, 인접한 픽셀들의 Mean과 Variance, Edge와 Texture 정보, Color Distribution 등이 있음.
즉, Local Statistics를 유지한다는 것은 특정 영역의 밝기, Texture, Edge 정보를 크게 변화시키지 않는다는 것을 의미함.
기존의 Mixup이나 CutMix의 경우 무작위로 잘라 붙이기 때문에 이미지 내 픽셀들의 상대적인 관계가 깨지게 됨.
Local Statistics를 유지하면서 픽셀을 이동하면, 이러한 구조적 일관성을 유지할 수 있음.
- Semantically Proportional Mixing (SnapMix): Class Activation Map (CAM)을 활용해서 Label Noise를 줄이는 증강 기법임. CAM을 활용하여 Semantically Salient Region을 기준으로 라벨을 혼합함. 즉, 잘린 Patch가 실제로 포함하는 정보의 중요도를 반영하여 라벨을 조정함.

- FMix: Fourier 공간에서 얻을 수 있는 Low-Frequency 이미지에 임계값을 적용하여 Random Binary Masks를 생성할 수 있음. 한 Color Region은 첫 번째 이미지에 적용하고, 또다른 Color Region은 두 번째 이미지에 적용하여 혼합하는 기법임.
- Fourier 변환을 통해, 공간 영역에서의 픽셀값을 주파수 공간에서의 주파수 성분으로 바꿀 수 있음. 저주파 이미지는 주파수 공간에서 저주파 성분만을 포함한 이미지를 다시 공간 영역으로 변환한 것임. 저주파 성분은 이미지의 Global Structure와 Smooth Transition을 포함함. 전반적인 형태는 유지하지만, Edge와 Texture와 같은 Detail은 제거됨.

- MixMo: Sub-Network를 통한 *Multi-Input Multi-Output (MIMO)의 학습을 진행하고, 기존의 Direct Hidden Summing Operations을 Mixing Block으로 대체함.
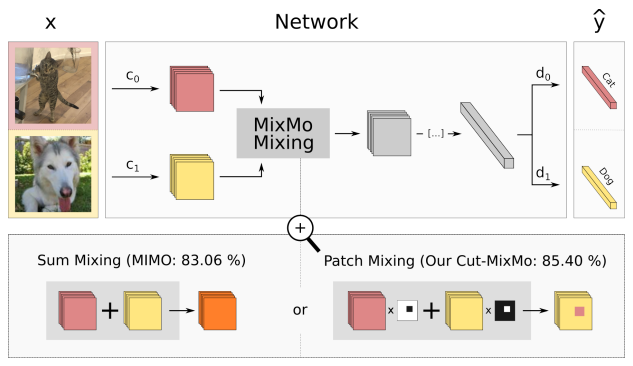
Input Data가 2인 경우를 나타냄. 2개의 Input을 Convolutional Layer $c_1, c_2$에 통과시켜 Shared Space에 Embedding하고 혼합한 뒤, 나머지 Layer와 Dense Layer $d_1, d_2$를 통해 2개의 Prediction을 얻음. 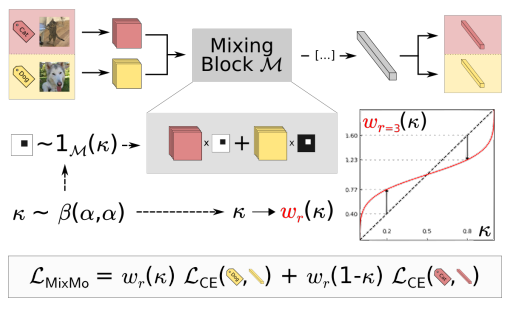
Mixing Block - $M$개의 입력을 각각 $M$개의 Sub-Network에 통과시켜 특징을 추출함.
- 기존의 MIMO 방식은 단순히 입력을 더하는 Summing을 사용하지만, MixMo는 CutMix 방식을 활용하여 입력 이미지의 패치를 서로 교환하는 방식 (Mixing Block)을 도입함.
- 혼합된 표현을 공유 네트워크에 전달하고, 마지막에는 각 Sub-Network마다 개별적인 Dense Layer를 배치해 각각의 Output을 생성함.
*MIMO는 여러개의 Input이 Network에 주어지고,
각 Input이 전체 구조안에서 개별적인 Sub-Network나 Branch에 의해 처리됨.
각 Sub-Network는 자기만의 Output을 만들어내고,
이는 입력 데이터의 서로 다른 측면이나 Feature를 나타냄.
- StyleMix: Pre-trained Style Encoder-Decoder Network를 사용하여 Input 이미지를 Content와 Style로 분리하고, Content와 Style을 독립적으로 혼합하여 새로운 샘플을 만드는 기법임.
- 기존의 Mixup 등의 증강 기법들은 Content와 Style을 구분하지 않고 단순히 픽셀을 혼합함. CNN이 학습할 때 Content (e.g., 형태, 구조, 윤곽)보다 Style (e.g., 색상, 질감, 명암)에 집중하는 문제가 발생할 수 있음.
- 예를 들어, 코끼리 사진을 학습할 때 Color에만 집중하면 Content가 다르더라도 회색이면 코끼리라고 인식할 수 있음.
- 기존의 Mixup 등의 증강 기법들은 Content와 Style을 구분하지 않고 단순히 픽셀을 혼합함. CNN이 학습할 때 Content (e.g., 형태, 구조, 윤곽)보다 Style (e.g., 색상, 질감, 명암)에 집중하는 문제가 발생할 수 있음.

- RandomMix: 여러 Image Mixing 데이터 증강 기법에서 무작위로 선택하여 이미지에 적용하는 방법임. 즉, Mixup, CutMix, ResizeMix, Fmix 등의 기법을 랜덤하게 선택 및 적용함.
- Mini Batch 내에서 무작위로 샘플 Pairing을 선택하고, 미리 정의된 증강기법 목록에서 하나의 기법을 무작위로 선택함. 선택된 증강기법을 적용하여 새로운 샘플을 생성함.

- MixMatch: 하나의 이미지를 $K$번 증강하고, 모든 $K$개의 이미지를 Classifier에 입력함. 이후, $K$개의 Prediction을 평균하고, Average Prediction을 Sharpening하기 위해서 Distribution의 Tmperature를 조절함. 이 방법은 Semi-Supervised Learning에서 유용함.
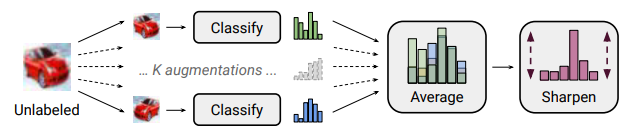
- ReMixMatch: MixMatch의 확장 방법으로, Distribution Alignment와 Augmentation Anchoring을 도입함.
- Distribution Alignment:
- Unlabeld Data의 예측 분포가 실제 Labeld Data의 분포와 유사하도록 조정함.
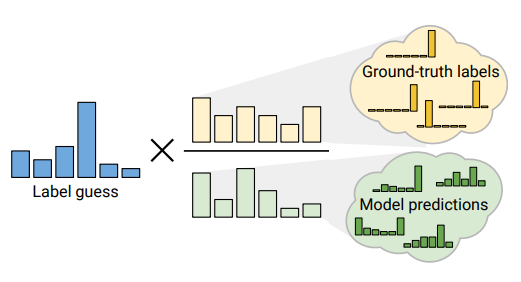
- Unlabeld Data의 예측 분포가 실제 Labeld Data의 분포와 유사하도록 조정함.
- Augmentation Achoring:
- 입력 이미지에 각각 Weak Augmentation과 Strong Augmentation를 적용함.
- Strong Augmentation 단계에서는 AutoAugment 기반의 CTAugment를 도입함. CTAugment는 신뢰도를 기반으로 증강 적용 강도를 동적으로 조정함. 즉, 예측 확률이 높으면 강한 증강을 적용하고, 예측 확률이 낮으면 약한 증강이 적용됨.
- Weak Augmented Image의 Prediction을 Strong Augmented Image의 Target으로 사용함.
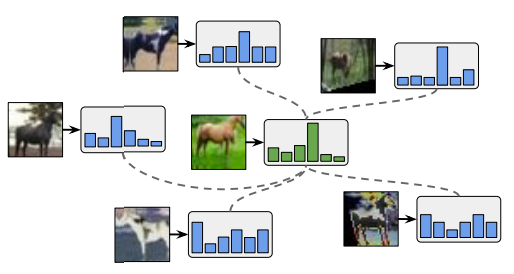
- Distribution Alignment:
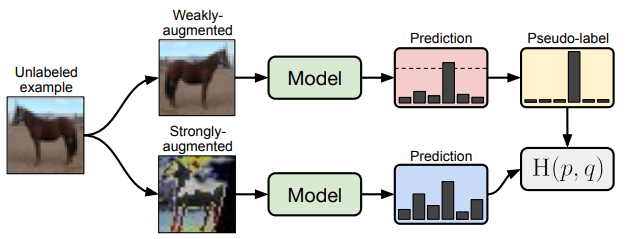
- FixMatch: Unlabeld Data에 대해 약한 증강과 강한 증강을 각각 적용하고, 약한 증강이 적용된 데이터의 예측값이 임계값 이상인 경우 Pseudo Label로 지정함. 그리고, 강한 증강이 적용된 이미지와 크로스엔트로피 Loss를 적용함. 이를 통해 Semi-Supervised Learning의 성능을 향상시킬 수 있음.
- AugMix: Training Data와 Test Data 간의 분포 차이를 줄이기 위한 데이터 증강 기법임. 입력 이미지에 대해 $M$개의 Random Augmentation을 서로 다른 강도로 적용하고, 결합하여 새로운 이미지를 생성함.


- Simple Copy-Paste: 한 이미지에서 Instance를 복사하여 다른 이미지에 붙여넣어 새로운 이미지를 생성하는 방법으로, Instance를 다양한 Scale로 조정하여 증강할 수 있음.

- Improved Mixed-Example Data Augmentation: Mixup과 같이, 두 개의 이미지를 Linear Combination하여 새로운 이미지를 생성하는 Label Non-Preserving 데이터 증강 기법에 대한 분석을 통해, 데이터 증강에서 선형성이 항상 중요한 것이 아니라고 지적하며 Generalized 한 증강 기법 (Vertical Concat, Random 2×2 Patch Mixing, Random Block Mixing 등)을 제안함.

- Random Image Cropping and Patching (RICAP): 두 개의 이미지를 혼합하는 CutMix와 다르게, 네 개의 서로 다른 이미지에서 일부 Patch를 잘라내어 결합함. Label은 잘린 Patch 들의 크기에 비례하여 혼합됨.

- Cutblur: Super-Resolution 데이터 증강을 위한 기법으로, High-Resolution 이미지의 일부 Patch를 잘라내어 Low-Resolution 이미지에 붙이거나, 반대로 LR Patch를 HR 이미지에 붙이는 방법임.

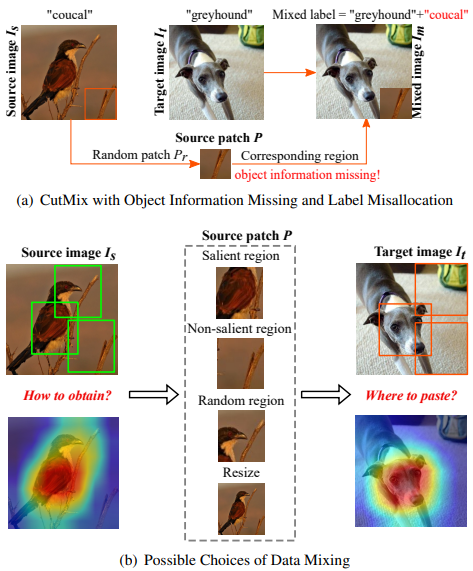
- ResizeMix: Source Image를 Target Image에 4가지 방식으로 붙이는 실험을 통해, Cutting-based Data Mixing에서 Saliency Information을 고려하는 것이 필수 요소가 아니고, *Label Misallocation과 ¶Object Information Missing을 동시에 피할 수 없음을 확인함. 이를 완화하기 위해, 이미지를 Small Patch로 Resize해서 다른 이미지에 붙이는 ResizeMix를 제안함.
- Salient Part: Grad-CAM을 이용해 주요 객체 영역에서 Patch를 선택
- Non-Part: Grad-CAM을 이용해 배경과 같은 비주요 영역에서 Patch를 선택
- Random Part: 무작위 위치에서 Patch를 선택
- Resized Source Image: 전체 Source Image를 축소하여 사용
*잘려나간 Patch가 객체와 같은 의미 있는 정보를 포함하지 않을 경우,
해당 이미지의 라벨이 불필요하게 혼합되는 문제로,
Label이 실제 이미지 의미와 맞지 않게 할당되는 것을 의미함.
¶이미지를 잘라 붙이는 과정에서, 객체의 일부가 손실되는 문제로

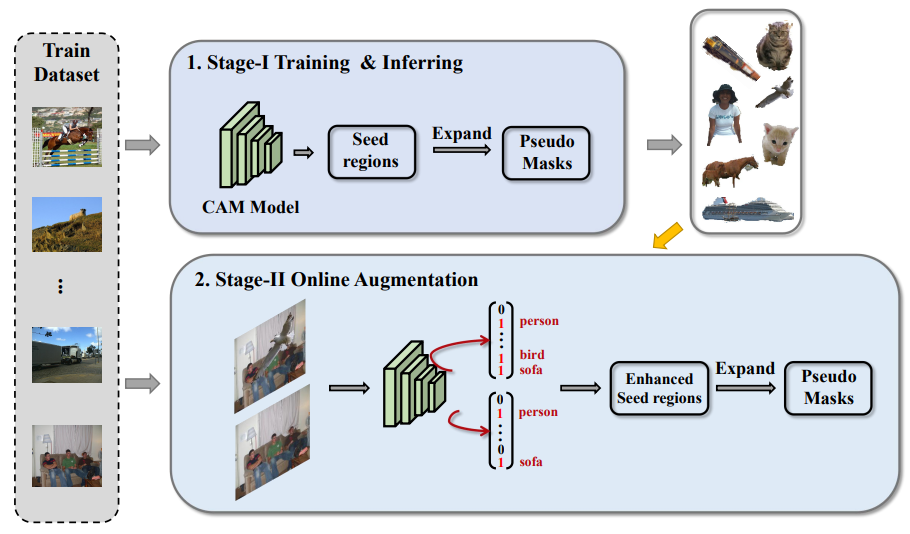
- ClassMix: 기존의 데이터 증강기법은 Classification에서는 효과적이지만, Semantic Segmentation에서는 동일한 효과를 발휘하지 못함. ClassMix는 Unlabeld Image으로부터 얻은 Semantic Segmentation 결과를 통해 증강을 수행함.
- 두 개의 Label이 없는 이미지 $A$와 $B$를 Network $f_\theta$에 입력하여 Semantic Segmenation을 수행함. 이를 통해, 예측 결과 $S_A$와 $S_B$를 얻음. 이후, $S_A$에서 무작위로 절반의 클래스를 선택하여 Binary Mask $M$을 생성함.
- Binary Mask $M$을 활용해서 새로운 증강 이미지 $X_A$와 새로운 Label $Y_A$를 생성함.
$$ X_A = M\cdot A +\left( 1-M \right)\cdot B $$ $$ Y_A = M\cdot S_A +\left( 1-M \right)\cdot S_B $$ - Netowrk가 $X_A$에 대해 예측한 결과가 $Y_A$와 일관되도록 학습을 진행함.

- Context Decoupling Augmentation (CDA): 기존의 데이터 증강 기법들은 동일한 Context를 가진 데이터를 증가시키기 때문에 객체를 구별하는 데 도움이 되지 않음. CDA는 특정 객체의 다양성을 증가시켜 Netowrk가 객체와 Context간의 의존성을 줄이도록 함. 즉, 객체 자체에만 집중하도록 증강을 수행함.

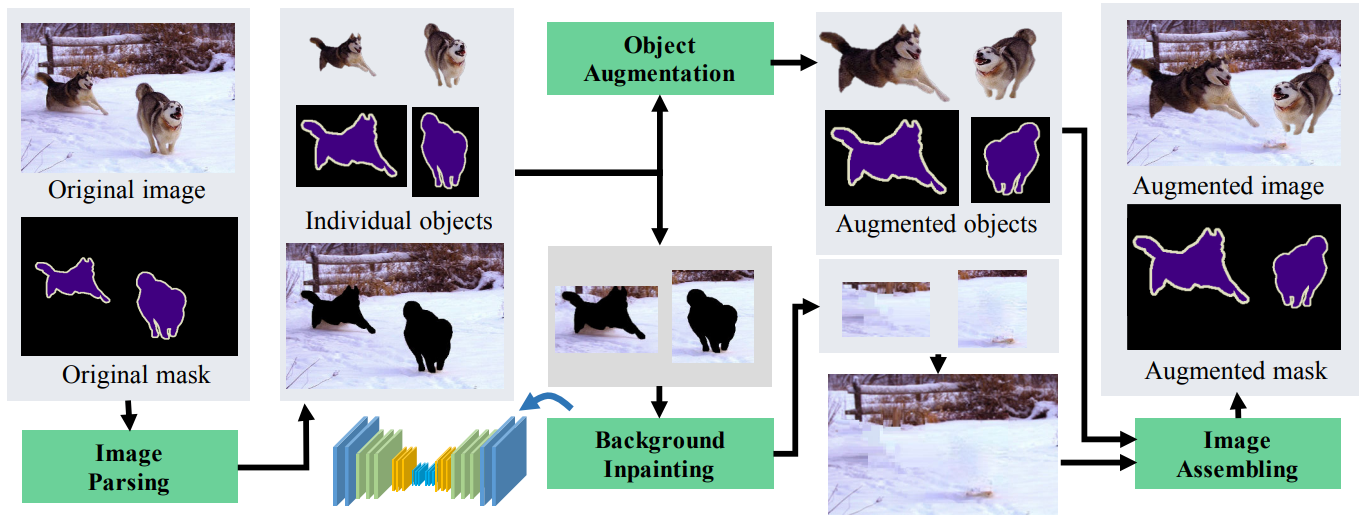
- ObjectAug: 기존의 방법들은 객체와 배경이 결합된 상태에서 증강이 되기 때문에 객체의 경계가 유지되지 않고 왜곡됨. 이를 해결하기 위해, ObjectAug는 Semantic Label을 활용해서 객체와 배경을 분리하고, 객체에 대해서만 증강을 수행함. 이후, 증강된 객체와 배경을 다시 결합하여 새로운 증강 이미지를 생성함.
- Image Parsing: 이미지에서 객체와 배경을 분리하는 과정
- Background Inpainting: 객체를 제거한 후 남은 배경을 복구하는 과정으로, ResNet50 기반 U-Net 모델을 활용하여 Inpainting을 수행

'Paper Review > Data Augmentation' 카테고리의 다른 글
| [Paper Review] Image Data Augmentation Approaches (~ 1. Basic Image Data Augmentation) (0) | 2025.02.27 |
|---|