This is a Korean Review of "Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions" published in IEEE Access
Introduction
- 다양한 Neural Networks중에서, CNN은 Convolution Layer를 사용하여 Image의 다양한 Feature를 학습함.
- Initial Layer는 Edge나 Line과 같은 Low-Level Feature에 집중하며, Deeper Layer는 더욱 구조화되고 복잡한 Feture에 집중함.
- CNN의 대안으로서, Vision Transformer(ViT)가 등장하였음. 이는 Self-Attention을 사용하여 *Long-Range Dependency를 효과적으로 포착할 수 있음.
- 하지만, 이러한 Neural Network가 *Overfitting에 빠지지 않게 하기 위해서는 많은 양의 데이터가 필요함. 이를 극복하기 위해 Data Augmentation 기법들을 활용할 수 있음. 이는 Image의 다양한 측면을 모델에 제공하여, 모델의 일반화 능력을 향상시킴.
*CNN는 Local Kernel을 사용해 좁은 영역 내 Feature를 학습하지만,
ViT는 Long-Range Dependency를 통해
이미지의 멀리 떨어진 부분들 간의 관계를 학습할 수 있음.
*Overfitting은 Training Data에서는 뛰어난 성능을 기록하지만,
Unseen Data인 Test Data에서는 좋지 않은 성능을 기록하는 현상임.
Taxonomy and Background
- Image 데이터는 일반적으로 RGB 3개의 Channel로 이루어져 있으며, Height × Width × Channel의 차원으로 표현됨.
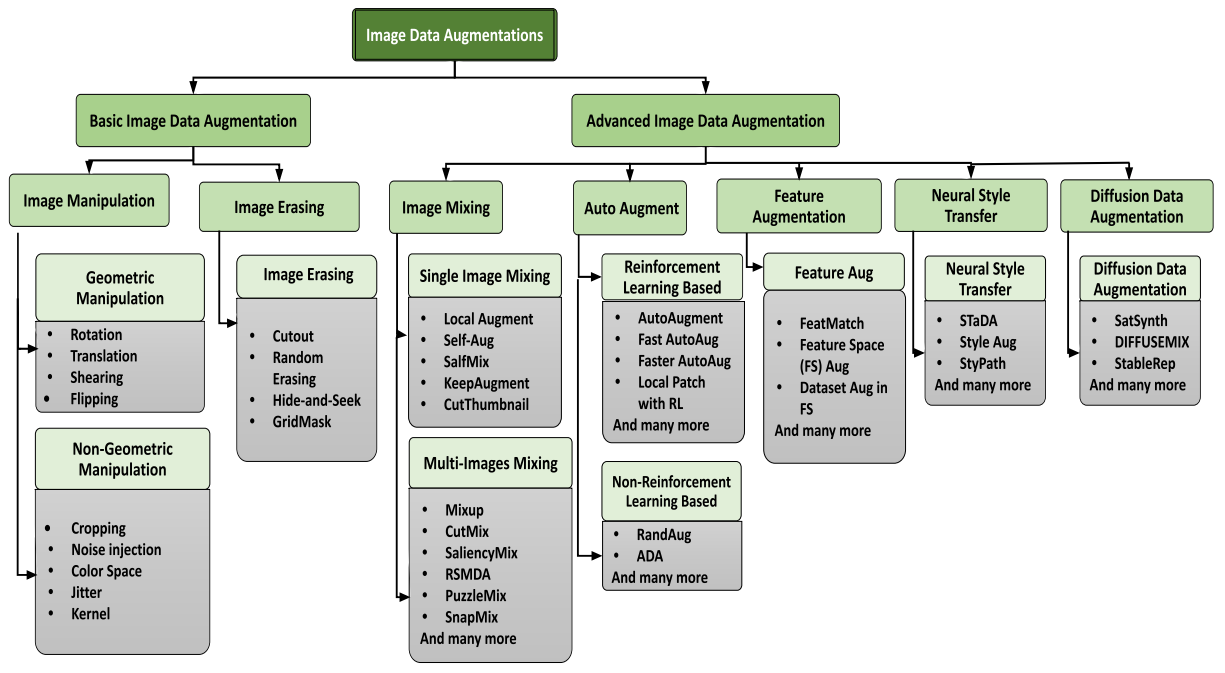
- Data Augmentation은 Basic Image Data Augmentation과 Advanced Image Data Augmentation으로 분류할 수 있음.
- Basic은 Data Augmentation를 위한 기초적인 기술을 다루며, Advanced는 더욱 복잡한 기술을 다룸.
1. Basic Image Data Augmentation
1.1. Image Manipulation
: 이미지의 위치와 색상을 변화시키는 기법
- Positional Manipulation은 픽셀의 위치를 조정하여 이미지를 변화시킴
- Color Manipulation은 픽셀값을 바꿔 이미지를 변화시킴.
1.1.1. Geometric Data Augmentation
: 이미지의 위치, 방향, Aspect Ratio를 포함하는 Geometric 특성을 수정하며, Rotation, Translation, Shearing, Flipping 등을 통해 이미지 내 픽셀 배열을 변형함.
- Rotation: 이미지를 0도에서 360도 사이의 특정 각도로 회전시킴. 회전 각도는 Hyperparameter이기 때문에 데이터셋의 특성에 따라 적절하게 결정해야 함.
- 예를 들어, MNIST의 숫자 6을 오른쪽으로 회전하면 9가 되는 문제가 있음
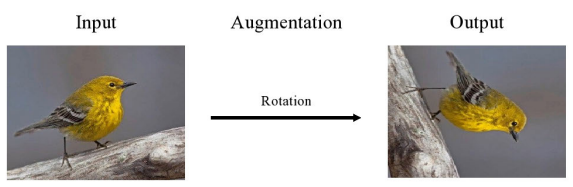
- Translation: 이미지를 위, 아래, 좌, 우로 이동시킴. 너무 큰 이동은 이미지의 형태를 크게 바꿀 수 있기 때문에 변형 강도는 신중하게 조절해야 함.
- 예를 들어, 숫자 8을 왼쪽으로 이미지 너비의 절반만큼 이동하면, 숫자 3처럼 보이는 문제가 있음
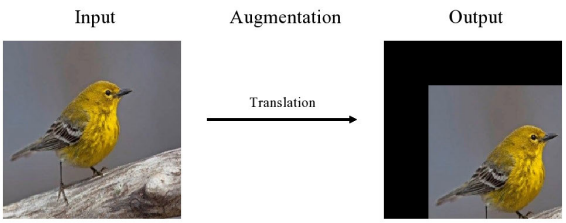
- Shearing: 이미지의 한 부분을 특정 방향으로 이동시키고, 다른 부분을 반대 방향으로 이동시킴. 과도한 Shearing은 이미지를 심하게 변형시키기 때문에 객체 인식을 어렵게 함
- 예를 들어, 고양이 이미지에 과도한 Shearing을 적용하면 고양이가 비정상적으로 늘어나거나 찌그러져 모델이 올바르게 분류하기 어려울 수 있음.
- Flipping: 이미지를 수평 또는 수직으로 반전시킴. CIFAR-100과 같은 잘 알려진 데이터셋에서 유용하게 사용되지만, 데이터셋의 특성에 따라 신중하게 적용해야 함.
- 예를 들어, 숫자 2를 수평으로 뒤집으면 숫자 6처럼 보일 수 있음.
1.1.2. Non-Geometric Data Augmentation
: Noise Injection, Cropping, Resizing, Color Space 등과 같은 이미지의 시각적 특성을 수정함. 너무 강한 변형은 원본 데이터의 중요 정보를 손상시킬 수 있기 때문에 데이터 증강과 기존 정보 보존 사이의 적절한 균형이 필요함.
- Cropping and Resizing: 이미지의 일부를 잘라내고, 다시 원래 크기로 조정함. 잘못된 잘라내기는 모델의 학습을 더 어렵게 하기 때문에 적절한 크기 및 적용 위치를 고려해야함.
- 숫자 8의 상단이나 하단을 잘라내면 숫자 0처럼 보임.
- Noise Injection: Feature를 학습하고 적대적 공격에 대한 방어 능력을 향상시켜 모델의 강건성을 향상시키는 기법임.
- Color Space: 각 RGB 채널 값을 개별적으로 변경하여 모델이 특정 조명 조건에 편향되지 않도록 함. 가장 직관적인 방법은 하나의 채널을 무작위 값으로 대체하거나, 0 또는 255로 채우는 것임. 하지만, 이는 비현실적인 색 변화를 만들어 실제 이미지에 대한 일반화 능력을 감소시킬 수 있음
- 국기처럼 색이 중요한 객체의 색상이 변하면 모델이 잘못 학습됨
- Jitter: 이미지의 Brightness, Contrast, Saturation, Hue를 무작위로 변경함. 4가지 Hyperparameter에 대해, 최소/최대 범위를 적절히 조절해야 함.
- 폐 질환 진단을 위한 X-ray 이미지의 Brightness를 너무 높이면, 폐의 윤곽이 희미해져 질병 진단이 어려워질 수 있음

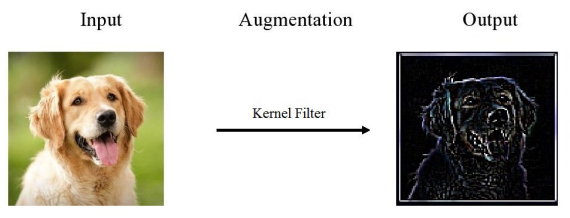
- Kernel Filter: Gaussian-Blur 또는 Edge Filter를 포함하는 $n\times n$ 크기의 Window를 적용하여, 이미지를 날카롭게 하거나 부드럽게 만듦.
- Gaussian Blur는 이미지를 부드럽게 만들고, Edge Filter는 Edge를 날카롭게 함.
- 과도한 Blur는 Details을 제거하여 중요 Feature를 구분하기 어렵게 함.
- 과도한 Sharpening은 Noise와 Artifact를 만들어낼 수 있음.
1.2. Image Erasing
: 이미지의 특정 부분을 제거하고, 0, 255, 또는 전체 데이터셋의 평균값으로 대체하는 기법으로, Geometric 또는 시각적 특성을 바꾸지 않음.
- Cutout: 이미지 내 일부 영역을 무작위로 제거하고, 그 부분을 0 또는 255 같은 일정한 값으로 채우는 방법

- Random Erasing: 이미지 내 일부 영역을 무작위로 지우는 것은 Cutout과 유사하지만, 지울지 말지와 지울 영역의 Aspect Ratio 및 크기도 무작위로 결정함.

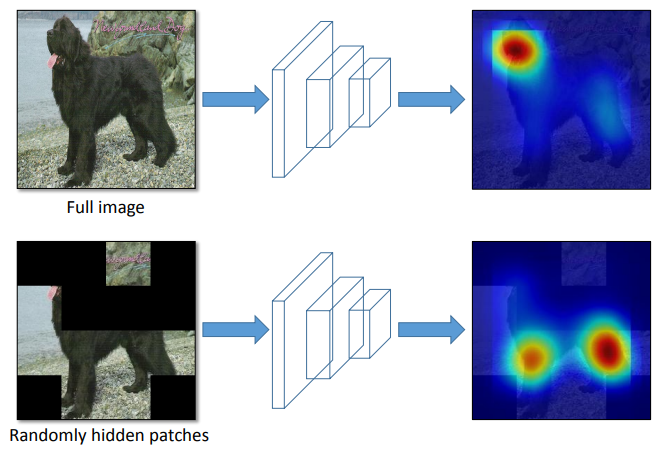
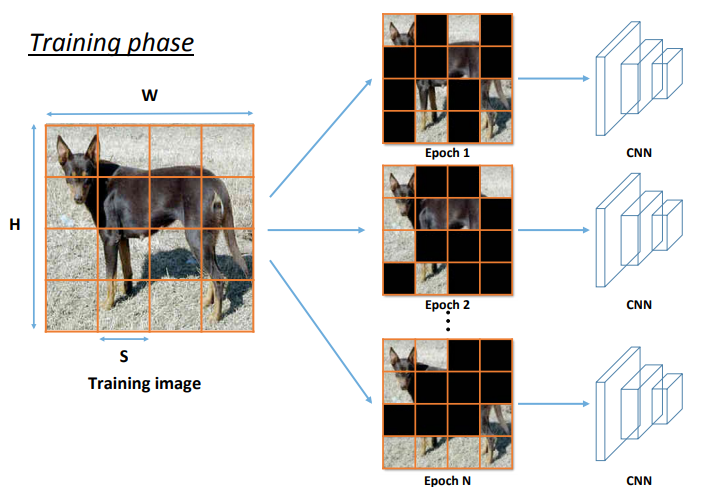
- Hide-and-Seek: 이미지를 균일한 크기의 작은 정사각형으로 나눈 후, 일부를 부작위로 제거하여 매 epoch마다 서로 다른 증강 이미지로 모델을 학습함. 이는 불완전한 정보로부터 물체를 인지하도록 하기 때문에 Occlusion에 강건한 모델을 만들 수 있음.
- 자율 주행에서 일부가 가려진 보행자나 차량을 인식할 수 있음.
- 그러나, 중요한 정보가 가려지면 진단 능력이 저하되는 의료 영상 같은 분야에서는 부정적인 영향을 미칠 수 있음
- GridMask Data Augmentation: 이는 무작위로 특정 영역을 지울 때 발생하는 문제를 해결함. 물체를 완전히 지우거나, Context 정보를 제거하는 과정은 적절한 균형이 필요함. 이를 위해 GridMask는 균일한 마스킹 패턴을 만들어 이미지에 적용함.

