This is a review of
"Decoupled Knowledge Distillation"
presented at CVPR 2022.
Introduction

Types of Knowledge Distillation
Logits-based method
- $(+)$ Computational and storage cost ↓
- $(-)$ Unsatisfactory performance
Feature-based method
- $(+)$ Superior performance
- $(-)$ Extra computational cost and storage usage
∴ Potential of logit distillation is limited.
Decoupled Knowledge Distillation
Target classifiation knowledge distillation $($TCKD$)$
- Binary logit distillation
Non-target classification knowledge distillation $($NCKD$)$
- Knowledge among non-target logits
Method
Reformulation
$$
p_i=\frac{\exp \left(z_i\right)}{\sum_{j=1}^C \exp \left(z_j\right)},\boldsymbol{p}=\left[p_1, p_2, \ldots, p_t, \ldots, p_C\right] \in \mathbb{R}^{1 \times C}
$$
Binary probabilities
$$
p_t=\frac{\exp \left(z_t\right)}{\sum_{j=1}^C \exp \left(z_j\right)},p_{\backslash t}=\frac{\sum_{k=1, k \neq t}^C \exp \left(z_k\right)}{\sum_{j=1}^C \exp \left(z_j\right)},\\ \quad \boldsymbol{b}=\left[p_t, p_{\backslash t}\right] \in \mathbb{R}^{1 \times 2}
$$
Probabilities among non-target classes
$$
\hat{p}_i=\frac{\exp \left(z_i\right)}{\sum_{j=1, j \neq t}^C \exp \left(z_j\right)},\quad \hat{\boldsymbol{p}}=\left[\hat{p}_1, \ldots, \hat{p}_{t-1}, \hat{p}_{t+1}, \ldots, \hat{p}_C\right] \in \mathbb{R}^{1 \times(C-1)}
$$
Vanilla KD
$$
\begin{aligned}
\mathrm{KD} & =\mathrm{KL}\left(\mathbf{p}^{\mathcal{T}} \| \mathbf{p}^{\mathcal{S}}\right) \\
& =p_t^{\mathcal{T}} \log \left(\frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}}\right)+\sum_{i=1, i \neq t}^C p_i^{\mathcal{T}} \log \left(\frac{p_i^{\mathcal{T}}}{p_i^{\mathcal{S}}}\right)
\end{aligned}
$$
$$
\begin{aligned}
\mathrm{KD} &= p_t^{\mathcal{T}} \log \left( \frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}} \right) + p_ {\backslash t} ^{\mathcal{T}} \sum_{i=1, i \neq t}^{C} \hat{p}_i^{\mathcal{T}} \left( \log \left( \frac{\hat{p}_i^{\mathcal{T}}}{\hat{p}_i^{\mathcal{S}}} \right) + \log \left( \frac{p_ {\backslash t} ^{\mathcal{T}}}{p_ {\backslash t} ^{\mathcal{S}}} \right) \right) \\ &= p_t^{\mathcal{T}} \log \left( \frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}} \right) + p_ {\backslash t} ^{\mathcal{T}} \log \left( \frac{p_ {\backslash t} ^{\mathcal{T}}}{p_ {\backslash t} ^{\mathcal{S}}} \right) + p_ {\backslash t} ^{\mathcal{T}} \sum_{i=1, i \neq t}^{C} \hat{p}_i^{\mathcal{T}} \log \left( \frac{\hat{p}_i^{\mathcal{T}}}{\hat{p}_i^{\mathcal{S}}} \right).
\end{aligned}
$$
$$\mathrm{KD}=\mathrm{KL}\left(\mathbf{b}^\mathcal{T} \| \mathbf{b}^\mathcal{S}\right) + \left(1-p_t^\mathcal{T}\right) \mathrm{KL}\left(\hat{\mathbf{p}}^\mathcal{T} \| \hat{\mathbf{p}} ^\mathcal{S}\right) $$
$$ \therefore \mathrm{KD}=\mathrm{TCKD}+\left(1-p_t^\mathcal{T}\right) \mathrm{NCKD}$$
- While NCKD focus on the knowledge among non-target classes, TCKD focus on the knowledge related to the target class.
Effects of TCKD and NCKD
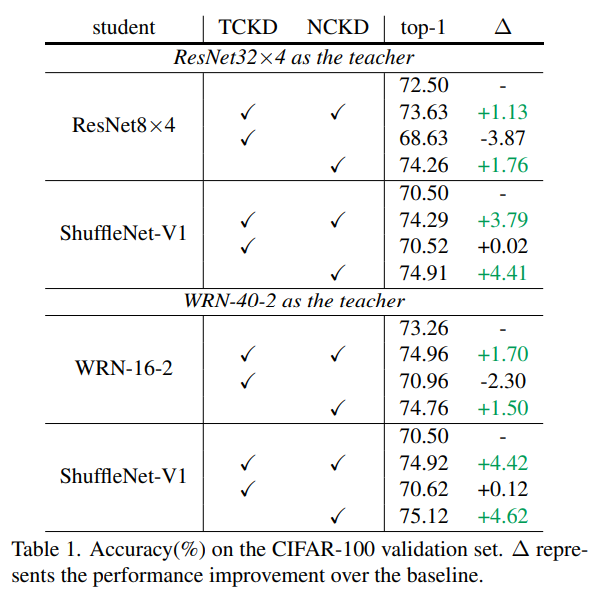
- Solely applying TCKD is unhelpful or even harmful.
- Performane of NCKD are comparable and even better than vanilla KD
∴ Target-class related knwoedge could not be as important as knolwedge among non-target classes.
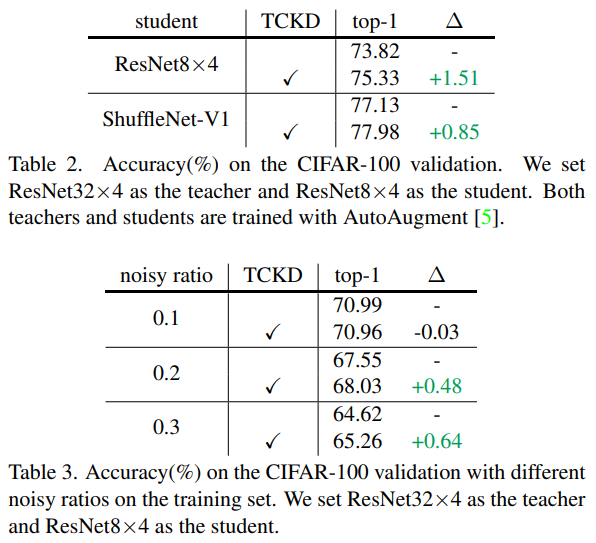

∴ The more difficult the training data is, the more benefits TCKD could provide.
Decoupled Knowledge Distillation
$$ \mathrm{KD}=\mathrm{TCKD}+\left(1-p_t^\mathcal{T}\right) \mathrm{NCKD}$$
- NCKD loss is coupled with $\left(1-p_t^\mathcal{T}\right)$: More confident predictions results in smaller NCKD weights. $($highly suppressed weights$)$
- Weights of NCKD and TCKD are coupled.
$$ \therefore \mathrm{DKD}=\alpha \mathrm{TCKD}+\beta \mathrm{NCKD}$$
Experiments
Ablation: $\alpha$ and $\beta$

CIFAR-100


ImageNet

COCO

Conclusions
- Reformulation of vanilla KD loss into two parts: TCKD and NCKD
- Decoupled Knowledge Distillation overcomes limitation of coupled formulation or effective transfer.
- Significant improvements on various datasets
'Paper Review > Knowledge Distillation' 카테고리의 다른 글
| [Paper Review] Knowledge Distillation from A Stronger Teacher (0) | 2024.11.25 |
|---|---|
| [Paper Review] Multi-level Logit Distillation (0) | 2024.11.25 |
| [Paper Review] Distilling Knowledge via Knowledge Review (0) | 2024.11.25 |
| [Paper Review] Similarity-Preserving Knowledge Distillation (0) | 2024.11.25 |
| [Paper Review] Distilling the Knowledge in a Neural Network (0) | 2024.11.25 |